📝 Paper Summary
Modularized RAG pipeline
Query rewriting / query generation
ERRR optimizes RAG systems by first extracting the LLM's internal knowledge, then rewriting search queries to specifically target missing or verifiable information, rather than just broadening the search scope.
Core Problem
Standard RAG systems suffer from a 'pre-retrieval gap' where the user's initial query fails to retrieve the specific information the LLM actually needs to generate a correct answer.
Why it matters:
- Existing query rewriters (like Rewrite-Retrieve-Read) broaden search scope but ignore what the LLM already knows, leading to redundant or distracting retrieval results.
- Black-box LLMs often have relevant internal knowledge that, if not accounted for, leads to misalignment between the retrieved documents and the model's generation needs.
Concrete Example:
If a user asks about 'Passage C' but uses ambiguous keywords, a standard retriever might fetch 'Passage A' or 'B'. ERRR first extracts what the model knows about the topic, then generates a refined query specifically to find 'Passage C' or validate its internal knowledge, avoiding the distractors.
Key Novelty
Extract-Refine-Retrieve-Read (ERRR)
- Introduces a 'Parametric Knowledge Extraction' step where the LLM generates a pseudo-document reflecting its internal knowledge before retrieving.
- Uses this extracted knowledge to condition the query optimizer, ensuring the search query specifically targets information that validates or supplements the model's internal beliefs.
- Proposes a 'Trainable Scheme' using knowledge distillation to train a smaller model (T5-Large) as the query optimizer, reducing the cost of using large black-box LLMs for rewriting.
Architecture
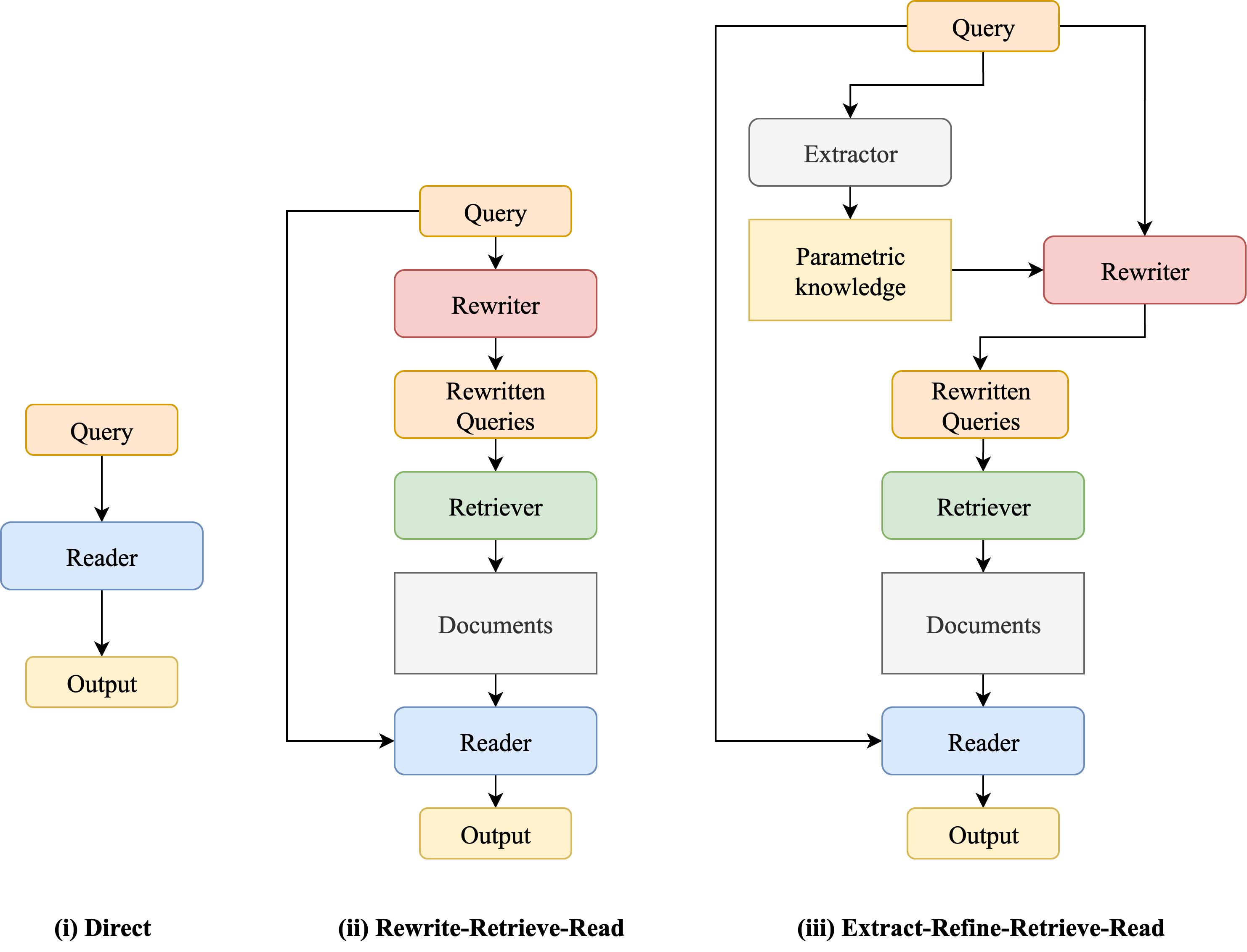
Comparison between the standard Rewrite-Retrieve-Read (RRR) pipeline and the proposed Extract-Refine-Retrieve-Read (ERRR) pipeline.
Evaluation Highlights
- Frozen ERRR outperforms the 'Rewrite-Retrieve-Read' baseline by +2.67 F1 on AmbigQA using the Contriever retriever.
- Trainable ERRR (using a distilled T5-Large) achieves +4.19 F1 over the Direct prompting baseline on PopQA with web search.
- Cost analysis on HotpotQA shows Trainable ERRR reduces latency to 1.34s (vs 2.37s for ReAct) and cost to $0.35 (vs $1.25 for ReAct).
Breakthrough Assessment
7/10
Offers a logical improvement to query rewriting by conditioning on internal knowledge. The distillation approach makes it practical. Good incremental advance over RRR.