📝 Paper Summary
Long-context Vision-Language Models (VLMs)
Efficient Attention Mechanisms
Linear Complexity Architectures
InfiniteVL combines Gated DeltaNet for linear-complexity long-term memory with Sliding Window Attention for local detail, enabling infinite context processing with constant memory usage and high throughput.
Core Problem
Existing VLMs struggle with a trade-off: window-based models lose long-term context, while linear attention models often lose fine-grained visual details needed for OCR and document tasks.
Why it matters:
- Quadratic complexity of Transformers prohibits processing long videos or continuous agent interactions on edge devices due to memory bottlenecks.
- Pure linear attention models (like Mamba or RWKV variants) historically underperform on information-intensive tasks like OCR compared to full-attention models.
- Resource constraints on edge devices require constant memory footprint to prevent Out-of-Memory errors during long streaming sessions.
Concrete Example:
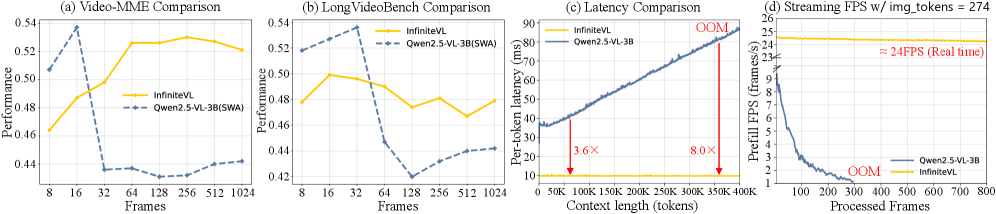
In streaming video understanding, a standard Transformer-based VLM (e.g., Qwen2.5-VL-3B) decays from ~10 FPS to <1 FPS after 200 frames and crashes (OOM) at frame 294 due to KV cache growth. InfiniteVL maintains a stable 24 FPS indefinitely.
Key Novelty
Hybrid Gated DeltaNet + Sliding Window Attention (InfiniteVL)
- Interleaves Gated DeltaNet layers (efficient, compressed global memory state) with Sliding Window Attention layers (precise local context) to balance long-range retention and fine-grained perception.
- Uses a 3-stage training pipeline (Distillation → Instruction SFT → Long-sequence SFT) to transfer knowledge from Transformers to the linear architecture efficiently.
Architecture
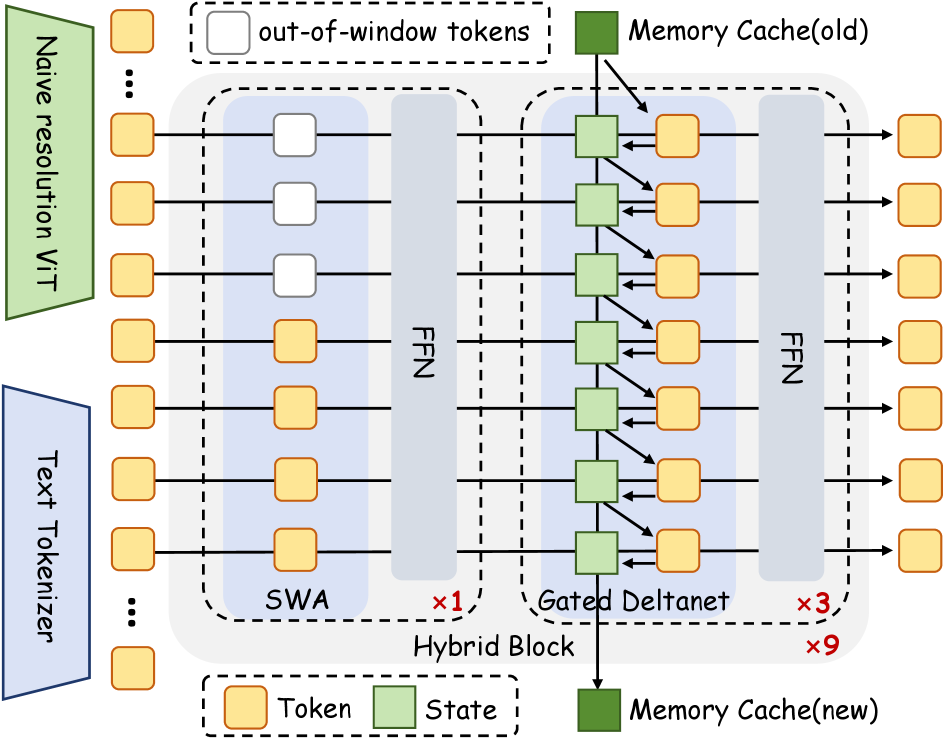
The InfiniteVL architecture pipeline and the internal structure of the Hybrid Block.
Evaluation Highlights
- Achieves >3.6x inference speedup vs. Transformer baselines at 50K context length, maintaining constant memory footprint.
- Sustains stable 24 FPS throughput in streaming video, whereas baselines crash after ~300 frames.
- Matches performance of leading Transformer VLMs (e.g., Qwen2.5-VL-3B) on OCR and Document Understanding benchmarks, areas where linear models typically struggle.
Breakthrough Assessment
8/10
Successfully bridges the gap between linear attention efficiency and Transformer-level performance on detail-oriented tasks, solving the 'detail vs. context' trade-off while enabling constant-memory streaming.