📝 Paper Summary
Modularized RAG pipeline
Quasar integrates unstructured text, structured tables, and knowledge graphs into a unified RAG pipeline by converting all sources into verbalized evidence and refining them through iterative GNN-based re-ranking.
Core Problem
LLMs struggle with long-tail entities and multi-hop questions requiring evidence from diverse modalities (text, tables, KGs), often failing to recall unpopular facts or aggregate dispersed information.
Why it matters:
- Standard LLMs and RAG systems primarily rely on text (web pages/Wikipedia), neglecting the vast amount of high-quality structured data available in online tables and knowledge graphs
- Questions about less popular entities (e.g., 'Lithuanian players in the German handball league') cause hallucinations in standard LLMs due to low frequency in pre-training data
- Existing heterogeneous QA systems often lack robust components for question understanding and evidence filtering, leading to noise that confuses the answer generator
Concrete Example:
For the question 'Which Chinese NBA player has the most matches?', a standard LLM might hallucinate based on popularity. Quasar solves this by retrieving from KGs (player lists), text (biographies), and tables (season stats), then aggregating these distinct modalities to find the correct answer.
Key Novelty
Unified Verbalization and GNN-based Filtering for Heterogeneous RAG
- Converts all data types—Knowledge Graph triples, table rows, and text sentences—into a uniform 'verbalized' textual format, allowing a single downstream model to process them identically
- Uses a Graph Neural Network (GNN) to model relationships between the question and retrieved evidence candidates, iteratively pruning the evidence pool from thousands to a high-quality top-k subset
Architecture
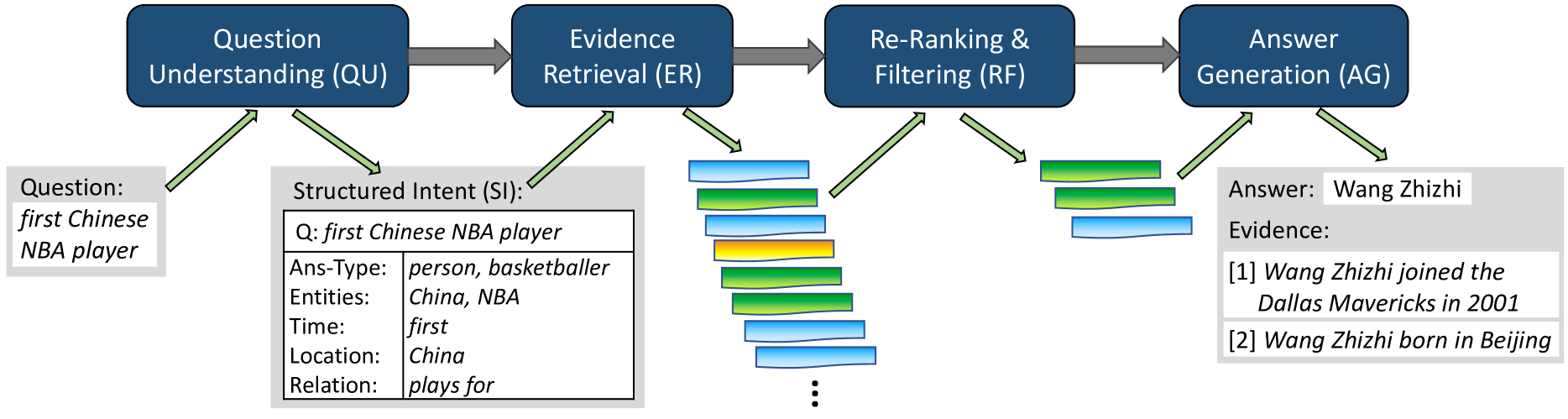
The four-stage pipeline of Quasar: Question Understanding, Evidence Retrieval, Re-ranking & Filtering, and Answer Generation.
Evaluation Highlights
- Achieves comparable or better performance than GPT-4 on the CompMix benchmark while using orders of magnitude fewer parameters (8B vs. estimated >1T)
- Establishes a new state-of-the-art on the TimeQuestions benchmark, significantly outperforming GPT-4 and Llama-3 baselines on temporal reasoning tasks
- Demonstrates that combining all three sources (Text + KG + Tables) yields higher accuracy than any single or dual-source combination (e.g., Text+Tables)
Breakthrough Assessment
7/10
Strong integration of heterogeneous sources with a unified interface. While the individual components (GNNs, verbalization) exist in prior work, the end-to-end efficiency and SOTA results on TimeQuestions are significant.