📝 Paper Summary
Conversational Recommender Systems (CRS)
Explainable Recommendation
COMPASS enhances conversational recommender systems by aligning knowledge graph embeddings with LLMs to generate interpretable, natural language summaries of user preferences from dialogue history.
Core Problem
Existing CRSs rely on latent vector representations for user preferences, which are opaque and lack explainability, while LLMs struggle to reason over domain-specific knowledge graphs due to the modality gap between structured graphs and unstructured text.
Why it matters:
- Vector-based preferences hide the 'why' behind recommendations, reducing system transparency and user trust.
- LLMs hallucinate or miss domain-specific item attributes (like specific actors or genres) without grounded knowledge from KGs.
- Current methods fail to perform cross-modal reasoning, unable to effectively synthesize dynamic dialogue history with static, structured knowledge graph data.
Concrete Example:
In a movie recommendation dialogue, a user might implicitly prefer 'sci-fi movies with time travel.' A standard CRS represents this as a hidden vector [0.2, -0.5, ...]. COMPASS explicitly generates the text: 'The user enjoys science fiction films featuring time travel elements,' allowing the system to verify and explain its subsequent recommendations.
Key Novelty
Two-stage Cross-Modal Alignment for Preference Summarization
- First, aligns the Knowledge Graph space with the LLM space via 'graph entity captioning,' teaching the LLM to translate graph embeddings into text descriptions.
- Second, employs 'knowledge-aware instruction tuning' to teach the LLM to synthesize dialogue history and KG-augmented context into structured preference summaries.
Architecture
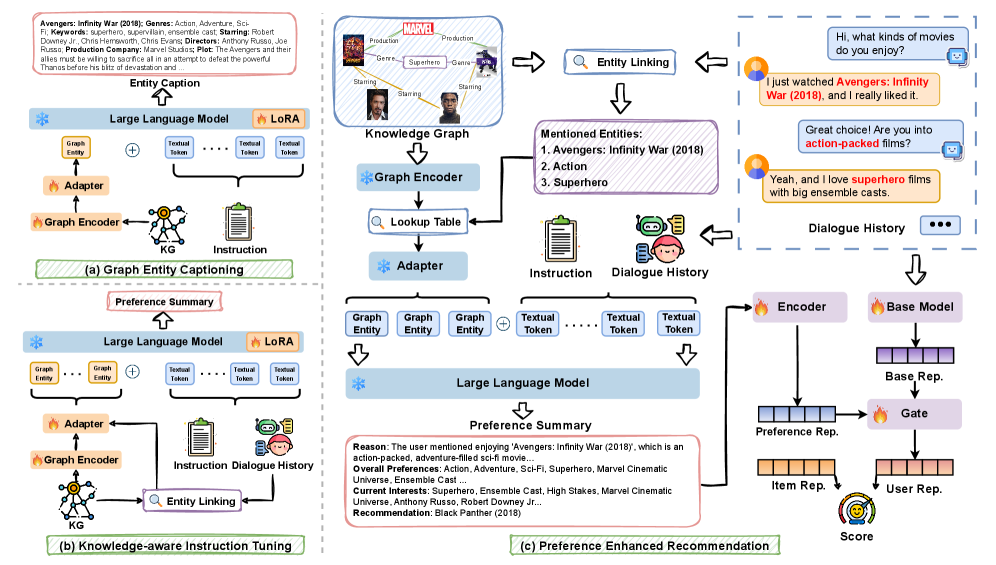
The overall architecture and two-stage training process of COMPASS.
Evaluation Highlights
- COMPASS improves recommendation performance when plugged into existing CRS models (results implied by 'demonstrate effectiveness' claim, specific numbers not provided in snippet).
- Generates human-readable preference summaries that capture both overall preferences and current interests.
- Successfully bridges the modality gap, enabling LLMs to reason over structured KG data without architectural modifications to the base CRS.
Breakthrough Assessment
7/10
Novel approach to bridging the KG-LLM modality gap for explainability. While the core idea of using LLMs for summaries is established, the specific two-stage alignment and plug-and-play gating mechanism for existing CRSs is a strong contribution.