📝 Paper Summary
Knowledge-aware recommendation
LLM-enhanced recommendation
SPiKE improves recommendation by generating semantic profiles for all entities using LLMs and propagating them through a Knowledge Graph to capture both attribute-level and structural preferences.
Core Problem
Acquiring rich personal data for recommendation is difficult due to privacy and sparsity, while current profiling methods either lack structural context (LLM-only) or semantic depth (KG-only).
Why it matters:
- Profiles solely relying on KGs miss rich semantic details available in textual metadata (descriptions, reviews).
- LLM-only profiles are often limited to local context and cannot effectively propagate influence to distant, sparsely connected items.
- Existing hybrid approaches often confine profile signals to local user-item modeling rather than propagating them throughout the entire graph.
Concrete Example:
A KG-only model links a user to a movie but misses why they liked it (e.g., 'dark humor'). An LLM might infer 'dark humor' preference but fails to link it to other movies with that attribute if they aren't directly adjacent in the text prompt context.
Key Novelty
Semantic Profiles into Knowledge Graphs (SPiKE)
- Generates text profiles for *all* entities (items, users, and auxiliary nodes like genres/directors) using LLMs to capture specific attribute preferences.
- Injects these text profiles into the Knowledge Graph as additive signals during aggregation, allowing semantic nuances to propagate structurally.
- Uses a ResNet-like mechanism where profiles are added during message passing but removed afterwards to preserve the original KG embedding space.
Architecture
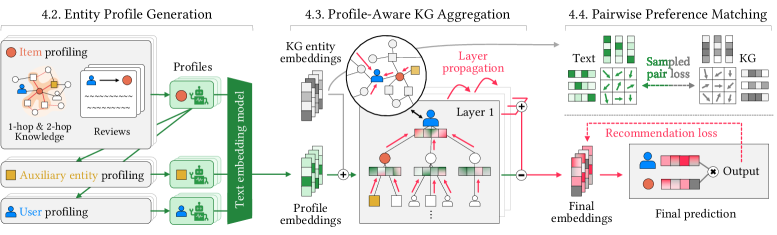
Overview of the SPiKE framework, detailing the three main components: Entity Profile Generation, Profile-aware KG Aggregation, and Preference Matching.
Evaluation Highlights
- Consistently outperforms state-of-the-art KG-based (e.g., KGIN, KGAT) and LLM-based recommenders across three real-world benchmarks.
- Demonstrates effective handling of sparse data by leveraging auxiliary entity profiles to bridge gaps between users and items.
- Ablation studies confirm the necessity of profiling all entity types (users, items, auxiliary), not just users or items alone.
Breakthrough Assessment
7/10
Solid hybrid approach addressing the specific limitations of LLM vs. KG profiling. While the components (LLM summarization, KG aggregation) are established, the 'profiling all entities' + 'inject-then-remove' propagation strategy is a clever integration.