📝 Paper Summary
Small Language Models (SLMs)
Efficient Transformers
Hybrid Architectures (Attention + SSM)
Hymba fuses attention and State Space Model (SSM) heads in parallel within the same layer, combined with learnable meta tokens, to boost efficiency and recall in small language models.
Core Problem
Standard Transformers suffer from quadratic complexity and high memory usage (KV cache), while State Space Models (SSMs) struggle with high-resolution memory recall, creating a trade-off between efficiency and performance.
Why it matters:
- Small Language Models (SLMs) are crucial for edge devices but are limited by memory and compute constraints
- Existing hybrid models stacking Attention and SSM layers sequentially introduce information bottlenecks when one layer type is ill-suited for a specific task
- Recall-intensive tasks remain a weakness for pure SSMs, limiting their utility in general-purpose benchmarks compared to Transformers
Concrete Example:
In commonsense reasoning, a pure Mamba model achieves 42.98% accuracy with efficient cache (1.9MB), while a Transformer achieves 44.08% but requires expensive cache (14.7MB). Hymba combines these strengths to achieve higher accuracy (45.59%) with compact cache.
Key Novelty
Parallel Hybrid-Head Architecture & Meta Tokens
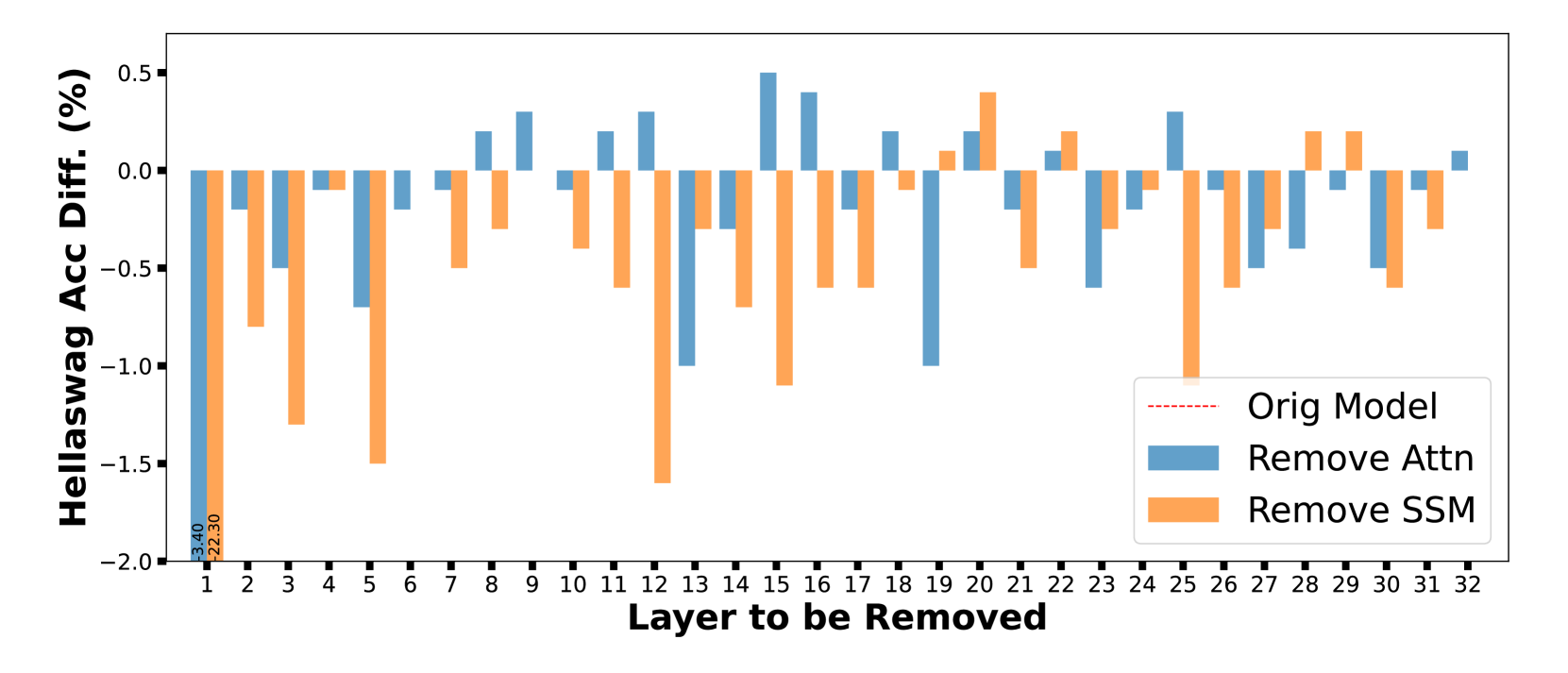
- Integrates Attention heads and SSM heads in parallel within the same layer, allowing simultaneous high-resolution recall (Attention) and efficient context summarization (SSM)
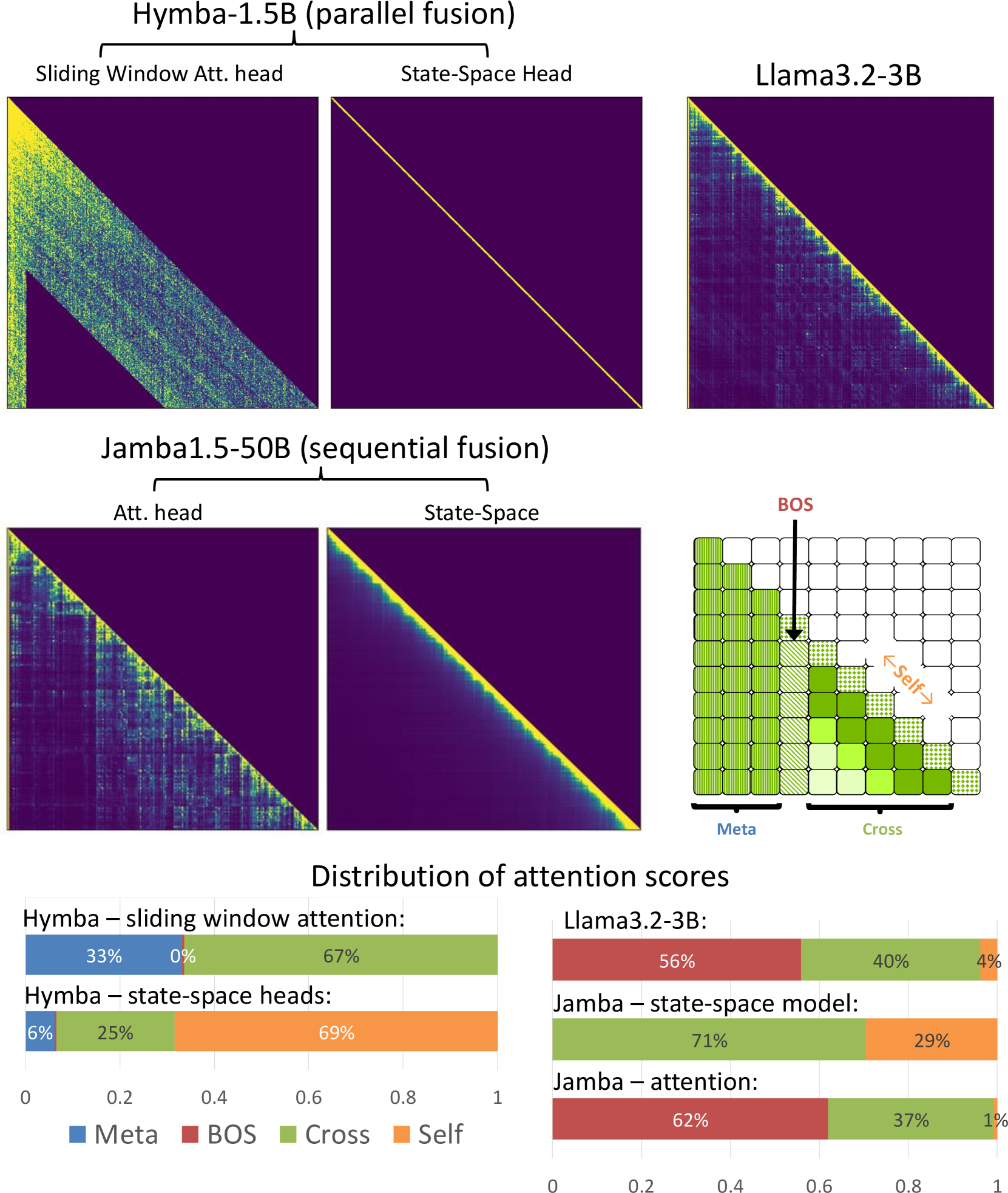
- Introduces learnable 'meta tokens' prepended to prompts that act as compressed world knowledge and cache initialization, preventing attention sinks and improving focus
Architecture
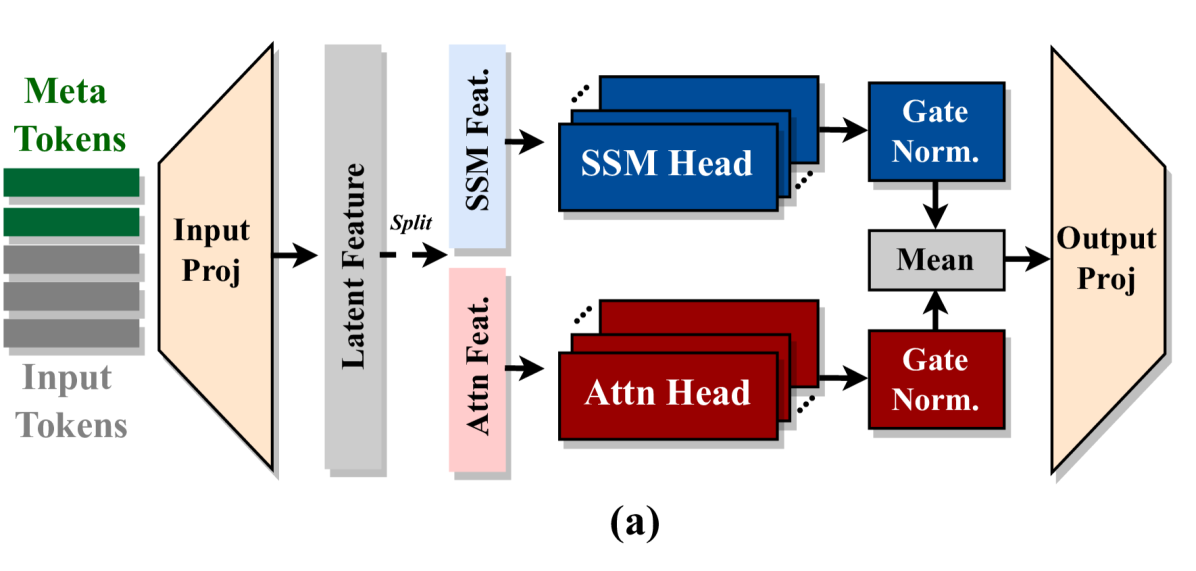
The Hybrid-Head Module architecture compared to sequential stacking
Evaluation Highlights
- Hymba-1.5B outperforms Llama-3.2-3B on average accuracy (61.06% vs 59.74%) despite being half the size
- Achieves 11.67x smaller KV cache size and 3.49x higher throughput compared to Llama-3.2-3B
- Surpasses Llama-3.2-1B on GSM8K and GPQA benchmarks after instruction tuning
Breakthrough Assessment
9/10
Significant architectural advance merging SSM and Attention in parallel rather than sequentially, achieving SOTA performance for sub-2B models with massive efficiency gains.