📝 Paper Summary
Agentic RAG pipeline
Generative Retrieval
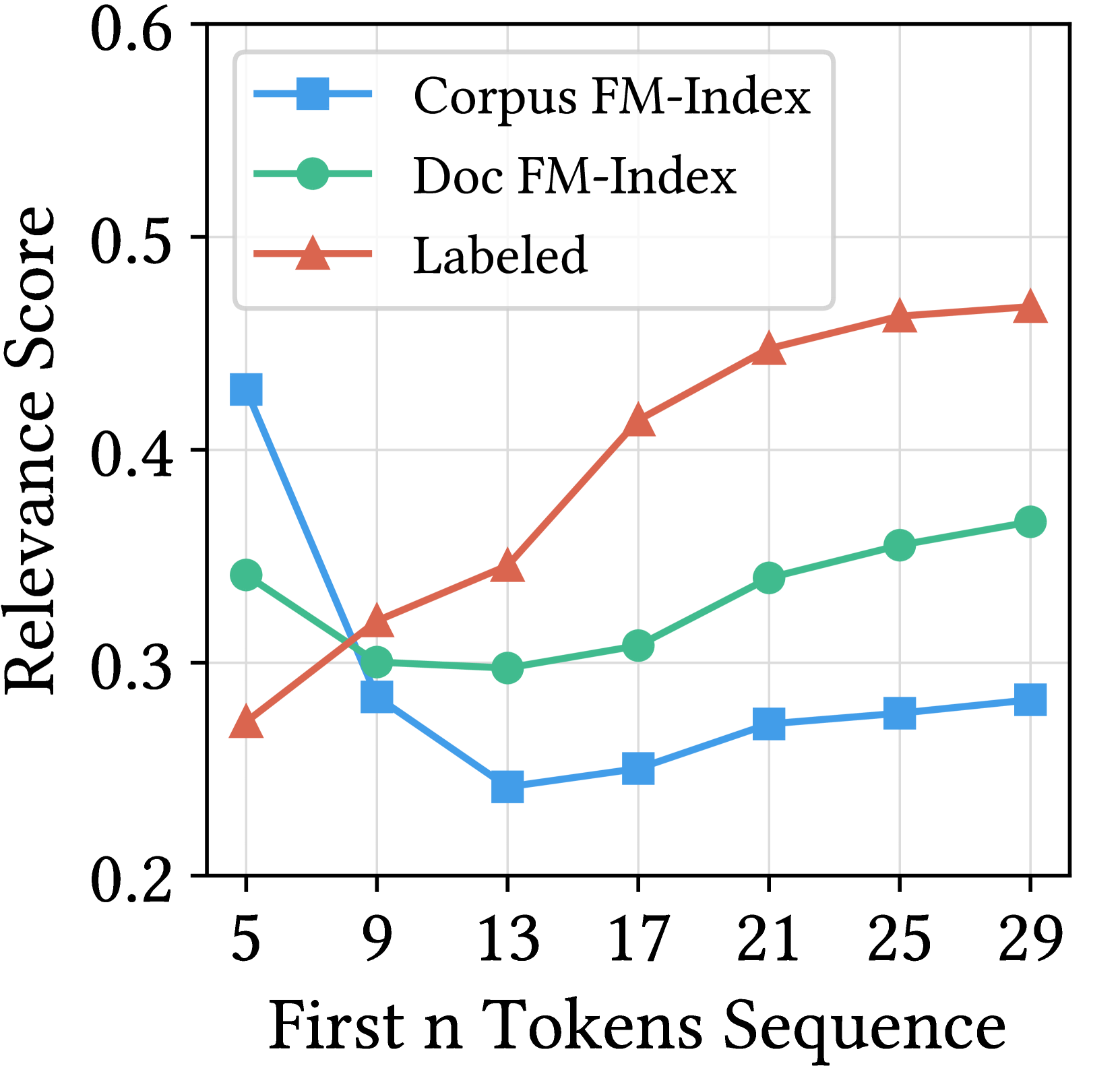
RetroLLM unifies retrieval and generation into a single auto-regressive process where the LLM directly generates corpus-constrained evidence strings using hierarchical FM-Index constraints and forward-looking relevance scoring.
Core Problem
Existing RAG methods rely on separate dense retrievers that break the joint optimization of retrieval and generation, while direct constrained generation suffers from severe false pruning where correct evidence paths are discarded early.
Why it matters:
- Separate retrievers increase deployment costs and prevent the LLM from learning internal correlations between retrieval and generation.
- Prefix-constrained beam search on large corpora fails because initial tokens of relevant and irrelevant documents often look identical (false pruning), leading to retrieval failure.
- Retrieved chunks often contain redundant tokens, wasting context window space and distracting the model.
Concrete Example:
When generating evidence under corpus constraints, an LLM might generate a prefix like 'The theory of relativity...'. This prefix exists in thousands of documents. If the beam search prunes the correct document's path because other documents look more probable initially, the model fails to retrieve the specific evidence needed, even if the prefix was correct.
Key Novelty
RetroLLM: Retrieval-in-Generation with Hierarchical Constraints
- Instead of a separate retriever, the LLM first generates 'clues' (keywords) to narrow down the search space to a subset of documents, effectively acting as its own coarse retriever.
- It then generates the actual evidence text, constrained to exist strictly within that document subset using an FM-Index, preventing hallucinations while retrieving.
- A 'forward-looking' decoding strategy peeks ahead at future text windows in the candidate documents to adjust current token probabilities, ensuring the generated evidence remains relevant to the query.
Architecture
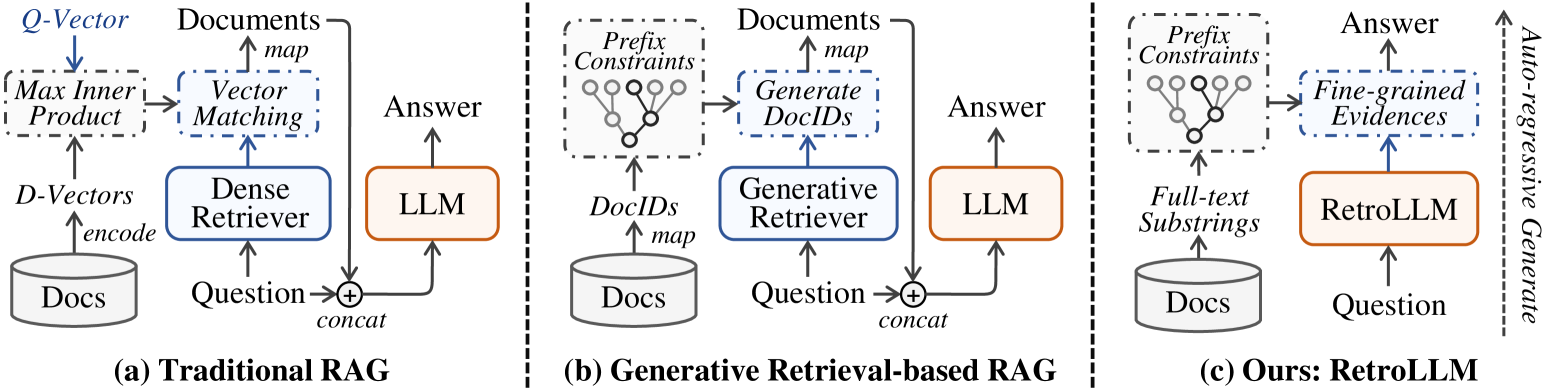
The unified auto-regressive decoding process of RetroLLM compared to standard RAG and Generative Retrieval.
Evaluation Highlights
- +3.45 EM (Exact Match) improvement on Natural Questions compared to the strong Self-RAG baseline using Llama-2-7B.
- Outperforms standard RAG (DPR + Llama-2-7B) by +17.16 EM on PopQA, demonstrating superior retrieval accuracy without a separate dense retriever.
- Surpasses 1-Retriever-K-Reader on 2WikiMultihopQA by +7.4 F1, showing effectiveness in multi-hop reasoning tasks.
Breakthrough Assessment
8/10
Significant architectural innovation by removing the separate index/retriever entirely and enforcing retrieval via constrained decoding. Effectively addresses the critical 'false pruning' failure mode of generative retrieval.