📝 Paper Summary
Multimodal Large Language Models (MLLMs)
Instruction Following
Visual Token Compression
The paper proposes compressing redundant visual tokens and inhibiting irrelevant text-to-image attention to significantly improve MLLM instruction-following capabilities without sacrificing multimodal understanding.
Core Problem
Multimodal Large Language Models (MLLMs) lag significantly behind their base LLMs in instruction-following capability, largely due to high information redundancy in the visual modality which interferes with precise text generation.
Why it matters:
- Replacing multimodal inputs with text-only inputs significantly increases instruction-following capabilities, indicating visual tokens actively degrade performance on complex instructions.
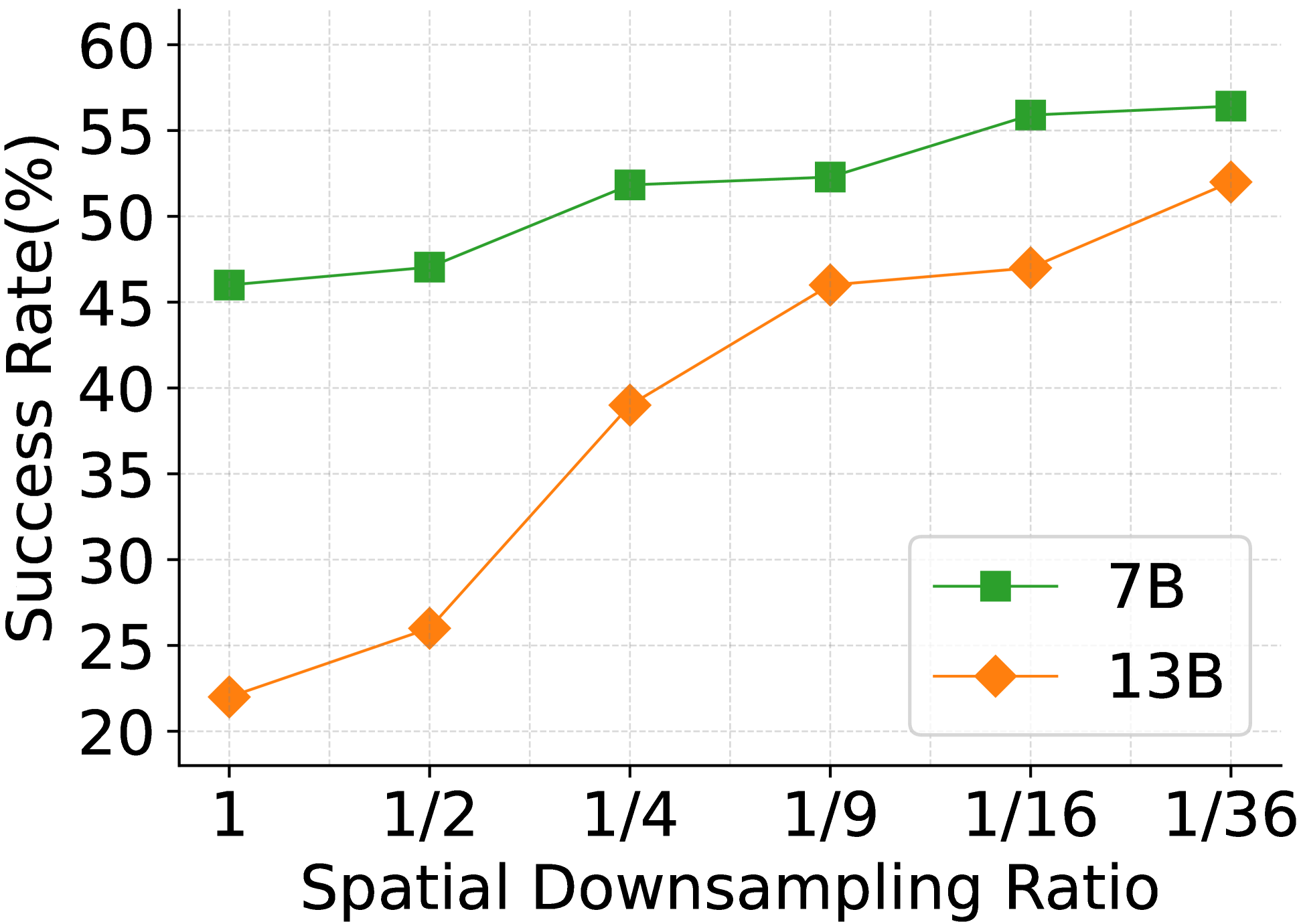
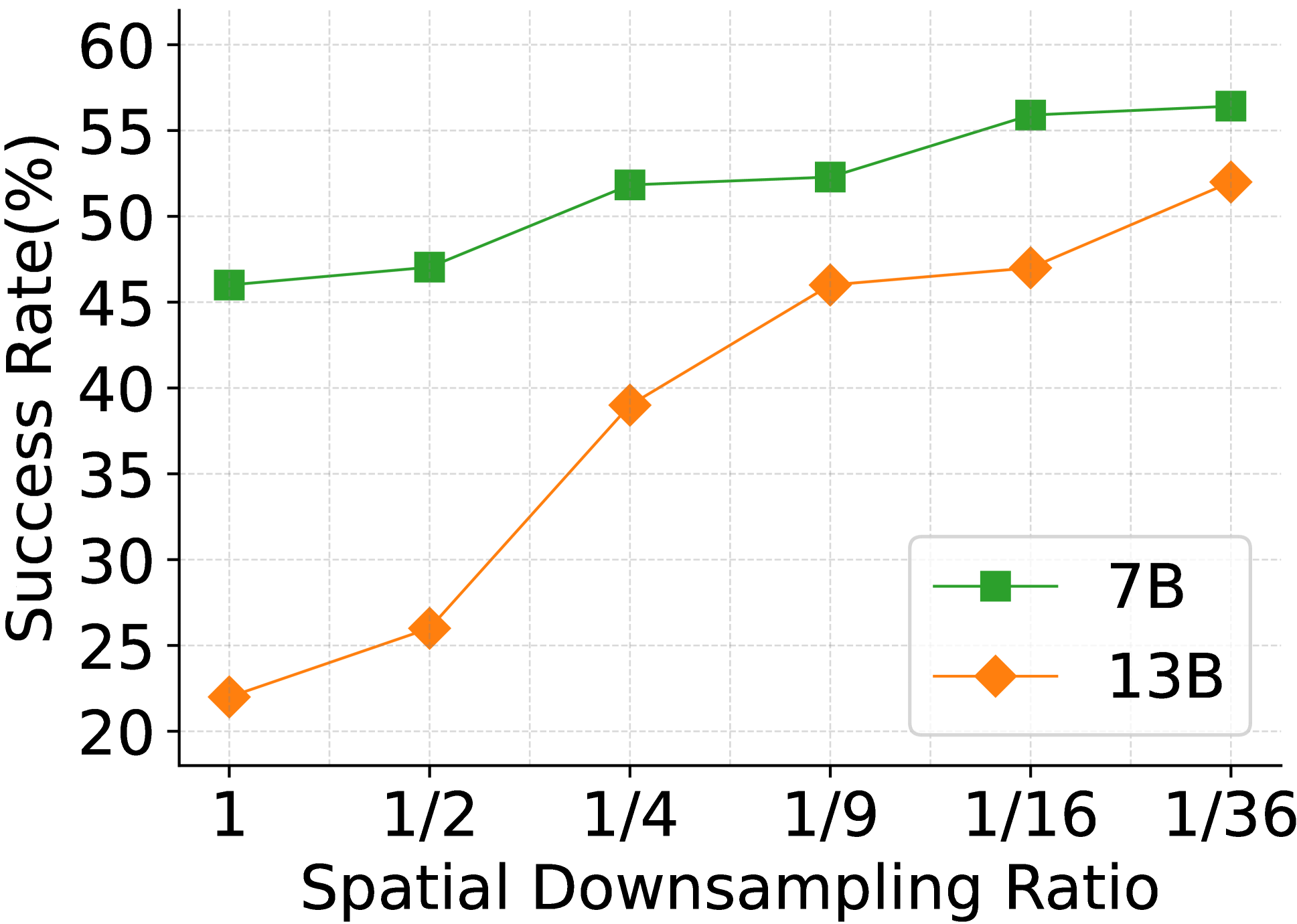
- Simple down-sampling of images improves instruction following but severely hurts multimodal understanding (e.g., VQA performance drops).
- Alignment with human intentions requires precise instruction following, which current MLLMs fail at compared to text-only LLMs.
Concrete Example:
In a pilot study, simply spatially down-sampling visual tokens improved instruction following (e.g., outputting JSON) by removing redundancy, but it destroyed the model's ability to answer detailed questions about the image content (multimodal understanding).
Key Novelty
Visual-Modality Token Compression (VMTC) & Cross-Modality Attention Inhibition (CMAI)
- VMTC identifies 'redundant' background image tokens using attention scores, clusters them to preserve semantic information, and merges them, keeping only essential foreground tokens.
- CMAI prevents the LLM from attending to irrelevant image tokens during text generation by calculating a 'focus score' (derived from text-to-text and text-to-image attention) and masking out low-score pairs.
Architecture
The overall architecture of the proposed method, detailing the VMTC module within the Vision Transformer and the CMAI module within the LLM.
Evaluation Highlights
- +9.5% improvement in instruction-following success rate compared to the LLaVA-1.5 baseline.
- Achieves state-of-the-art instruction following while maintaining multimodal understanding (e.g., only -0.4% drop on GQA vs. -2.1% for simple down-sampling).
- +7.8 score improvement on the MME benchmark compared to LLaVA-1.5.
Breakthrough Assessment
7/10
Identifies a novel correlation between visual redundancy and poor instruction following. The proposed solution effectively balances the trade-off between following complex instructions and retaining visual detail.