📝 Paper Summary
Speculative Decoding
Efficient LLM Inference
PLD+ accelerates LLM inference in input-guided tasks by using attention maps and hidden states to intelligently select text spans from the input as draft tokens without requiring auxiliary models or fine-tuning.
Core Problem
Autoregressive decoding in Large Language Models (LLMs) suffers from high latency due to sequential token generation, and existing speculative decoding methods often require training separate draft models or extensive fine-tuning.
Why it matters:
- Inference latency hinders the deployment of LLMs in interactive real-time applications like code editing and conversation
- Current tuning-free methods (like standard PLD) rely on simple string matching heuristics that lack semantic understanding
- Tuning-dependent methods impose significant computational overhead for training and maintenance across different model versions
Concrete Example:
In a code editing task, standard PLD might fail to identify the correct code block to copy if there isn't an exact n-gram match, whereas PLD+ uses attention mechanisms (induction heads) to semantically identify the relevant code span to copy from the input context.
Key Novelty
Artifact-Guided Speculative Drafting
- Leverages 'induction heads' (attention heads that perform prefix matching and copying) to rank potential draft spans from the input context
- Uses cosine similarity of hidden states to identify the most semantically relevant input spans when attention maps are insufficient
- Operates completely tuning-free, requiring no additional weights or training, by utilizing artifacts already computed during the standard forward pass
Architecture
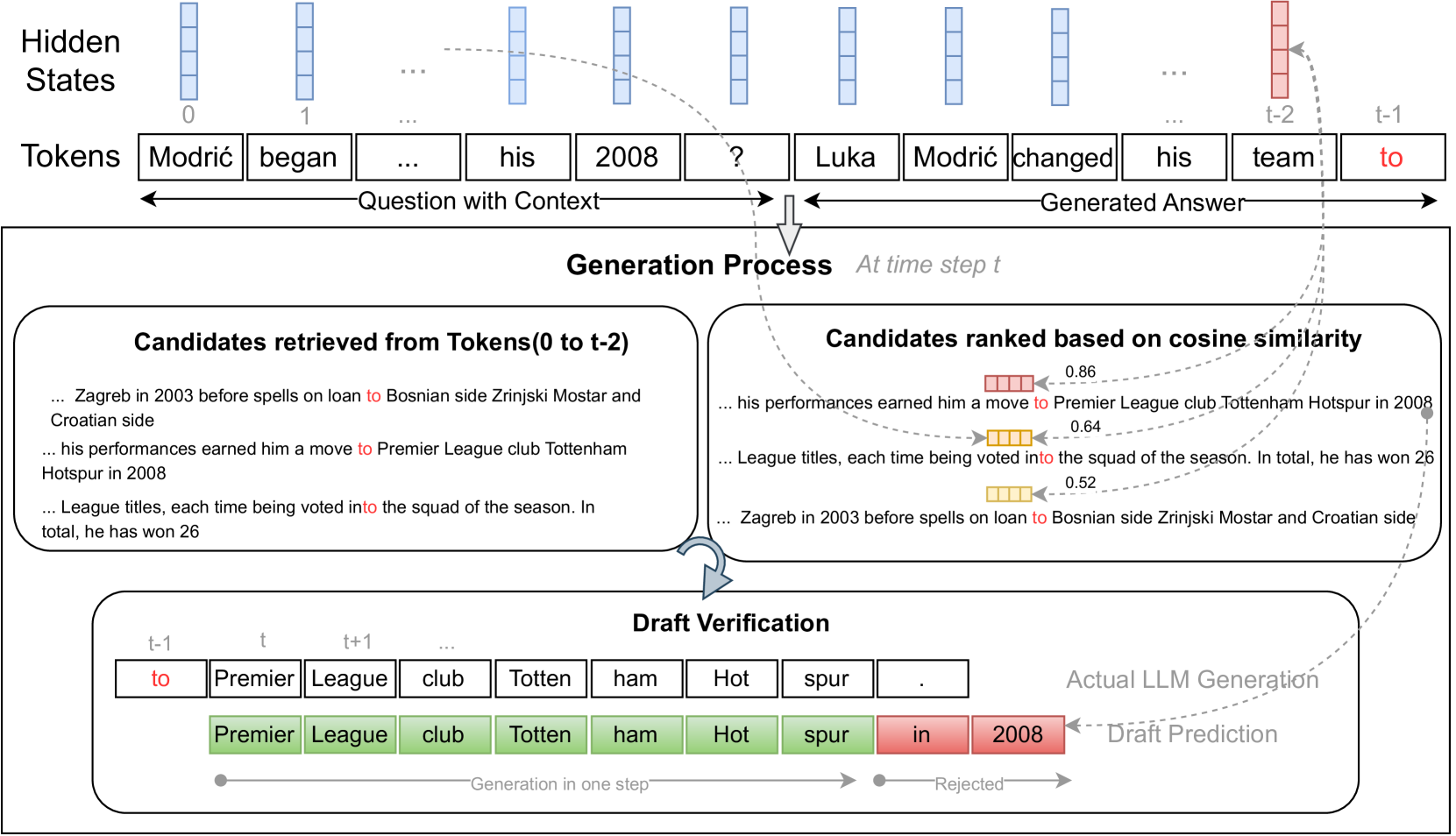
Overview of the PLD+ inference process, showing how draft tokens are selected using artifacts and verified.
Evaluation Highlights
- Outperforms state-of-the-art tuning-dependent method EAGLE on 4 out of 5 input-guided tasks in greedy settings
- Achieves up to 2.31x average speedup compared to standard autoregressive decoding
- Consistently outperforms tuning-free baselines (like PLD and Lookahead) across both greedy decoding and sampling modes
Breakthrough Assessment
7/10
Significant practical improvement for specific but common 'input-guided' workloads (editing, RAG). While not a universal architectural shift, it maximizes efficiency of existing artifacts without training overhead.