📝 Paper Summary
System 2 Reasoning in LLMs
Neurosymbolic Search
Game Playing Agents
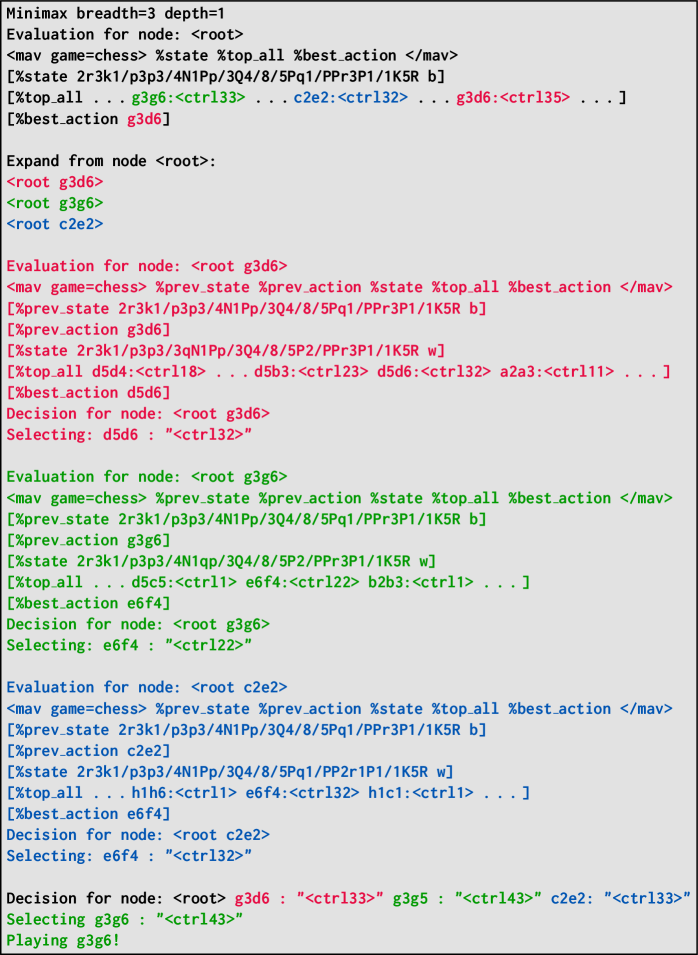
The paper introduces Multi-Action-Value (MAV) models that integrate world modeling, value functions, and policies to perform search-based planning in board games, either by guiding external MCTS or by internalizing search trees into the model's context.
Core Problem
LLMs struggle with reliable multi-step planning and reasoning in complex domains like board games because they lack consistent world models and ability to reason over possible futures.
Why it matters:
- Games astutely expose the inability of current LLMs to consistently reason over future states, serving as a critical testbed for general planning
- Standard LLMs rely on associative System 1 inference, prone to hallucinations, rather than deliberate System 2 planning required for reliability
- Existing game-playing LLMs often rely on external engines for legal move generation and state tracking, limiting their standalone reasoning capabilities
Concrete Example:
In a winning chess position, a standard LLM might play aimlessly or hallucinate an illegal move because it cannot look ahead to see the checkmate. MAV uses %top_k to evaluate moves and %best_action to force a decisive win, effectively 'seeing' the win via search.
Key Novelty
Multi-Action-Value (MAV) Model for Unified Planning
- Trains a single Transformer to act simultaneously as a world model (state tracking), policy, and value function for board games.
- Introduces 'External Search' where the MAV guides MCTS without any external game engine, using its own predictions for state transitions and legality.
- Introduces 'Internal Search' by training the model on linearized text representations of search trees, effectively distilling the search process into the forward pass.
Architecture

The input/output format for the Multi-Action-Value (MAV) model.
Evaluation Highlights
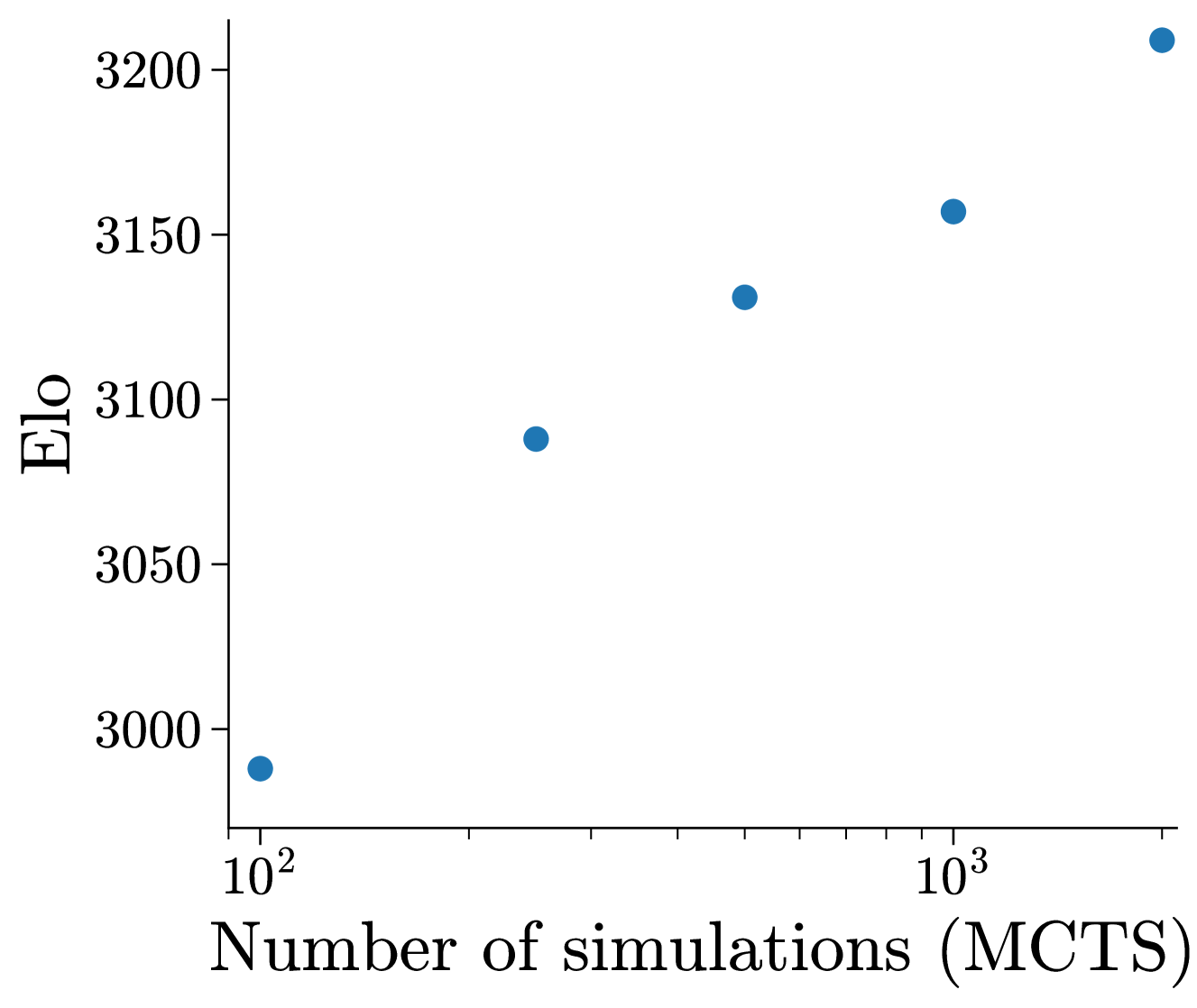
- MAV (2.7B) reaches Grandmaster-level performance in Blitz chess (Elo ~2905 against bots), significantly outperforming raw policy networks.
- Internal Search (MAV-IS) achieves an internal Elo of 2673 in Chess, outperforming the base MAV model (2568) without external search.
- External Search with MAV beats State-of-the-Art (SOTA) Chess LLMs like Grandmaster-Pro and typical engines like Stockfish 16 (at very low node counts).
Breakthrough Assessment
8/10
Demonstrates that LLMs can internalize the entire search loop (world model + search) without external engines, reaching SOTA chess performance with relatively small models (2.7B).