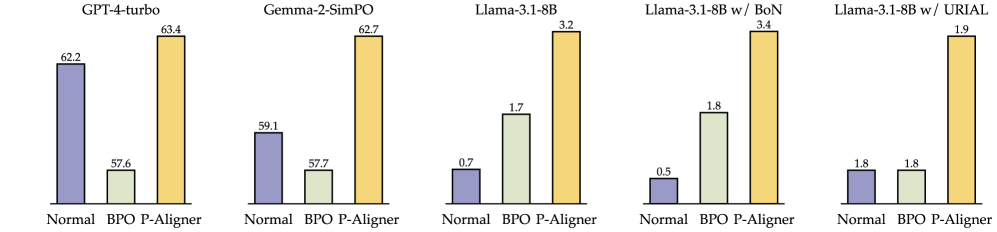📝 Paper Summary
Instruction Tuning
Preference Alignment
Prompt Engineering
P-Aligner is a lightweight module that rewrites user instructions into principled, preference-aligned versions before they reach the LLM, trained on a synthetically generated dataset built via Monte-Carlo Tree Search.
Core Problem
Even aligned LLMs often fail to produce safe or helpful content when user instructions are flawed (ambiguous, wrong tone, missing context), and existing fixes like prompt engineering or heavy re-training are costly or inconsistent.
Why it matters:
- Users frequently provide suboptimal prompts, causing capable models to fail on safety or helpfulness tasks.
- Existing instruction refinement methods either rely on expensive test-time search or heuristic data that lacks explicit alignment principles.
- Directly retraining massive LLMs for every edge case is computationally prohibitive compared to optimizing the input.
Concrete Example:
A user might ask a sensitive question with a disrespectful tone. A standard LLM might refuse or generate toxic content. P-Aligner rewrites this input into a polite, context-rich instruction, guiding the LLM to provide a helpful and safe response without altering the core intent.
Key Novelty
Principled Instruction Synthesis via MCTS (P-Aligner)
- Treats instruction refinement as a search problem where each step applies a specific alignment principle (e.g., 'add context', 'fix tone') to rewrite the prompt.
- Uses Monte-Carlo Tree Search (MCTS) to explore the space of possible rewrites, scoring them by how well an off-the-shelf reward model rates the resulting LLM responses.
- Distills this search process into a lightweight rewriter module (P-Aligner) trained on the resulting high-quality synthetic dataset (UltraPrompt), enabling fast inference without search.
Architecture
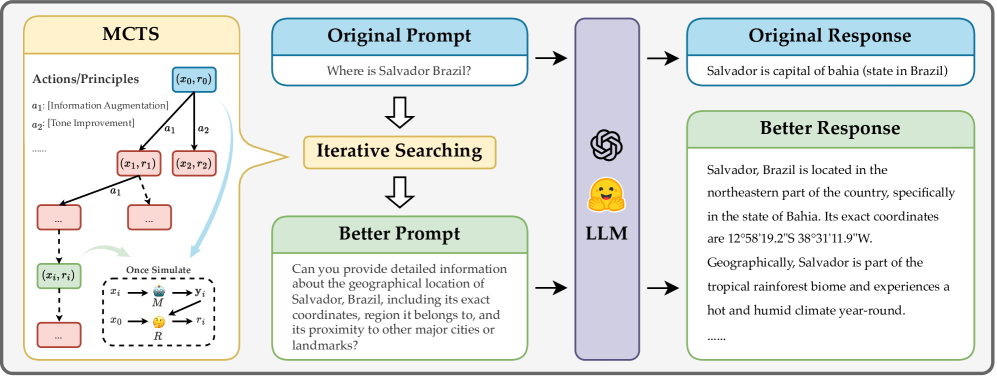
The principled instruction synthesis pipeline using MCTS. It shows the process of expanding instruction nodes using specific principles, scoring them via a proxy Reward Model on LLM outputs, and updating the tree.
Evaluation Highlights
- +28.35% average win-rate improvement on GPT-4-turbo across multiple benchmarks compared to using raw instructions.
- +8.69% average win-rate improvement on Gemma-2-SimPO, showing benefits for both open and closed models.
- Outperforms the BPO baseline on Vicuna Eval (+28.75%) and Self-Instruct Eval (+35.32%) with GPT-4-turbo.
Breakthrough Assessment
7/10
Strong empirical results and a clean methodology for synthesizing alignment data. While concept of rewriting is known, the MCTS-driven principle-based synthesis offers a more rigorous data generation pipeline than prior heuristics.