📝 Paper Summary
Contrastive Decoding
Hallucination Suppression
CDA is a training-free decoding method that estimates the uncertainty of parametric and contextual knowledge to dynamically weight their usage or trigger abstention when neither is relevant.
Core Problem
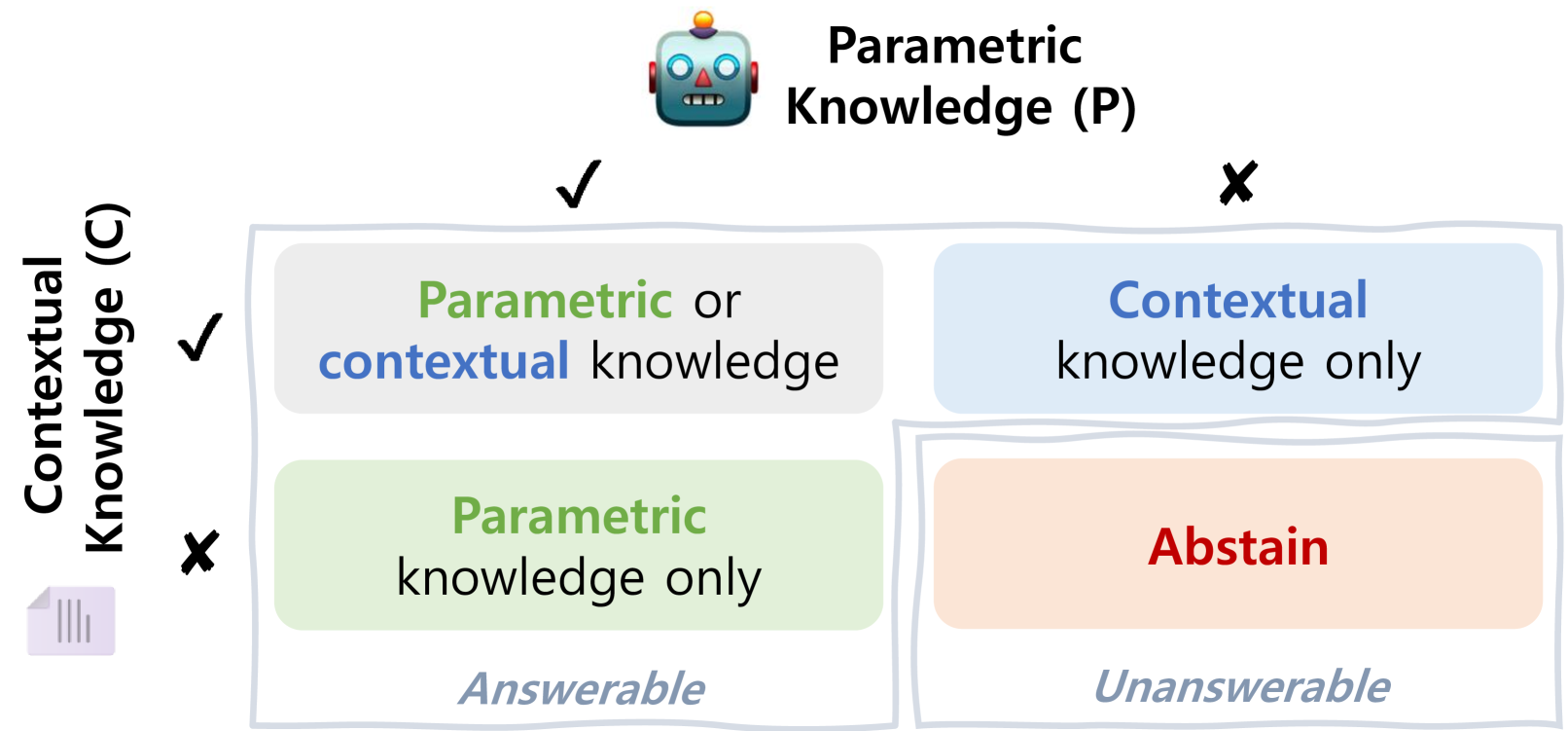
Existing LLMs often hallucinate answers when lacking both internal (parametric) and external (contextual) knowledge, and current decoding methods fail to handle the scenario where neither source is reliable.
Why it matters:
- Compelling models to answer when they lack information leads to severe hallucinations and loss of user trust
- Current Context-Aware Contrastive Decoding (CCD) methods assume at least one knowledge source (internal or external) is always correct, failing in 'unanswerable' edge cases
- Real-world applications require models to admit ignorance rather than fabricate plausible-sounding falsehoods
Concrete Example:
When asked a question where the model's pre-training data is outdated (low parametric relevance) and the retrieved context is irrelevant (low contextual relevance), standard models will force an incorrect answer. CDA detects high uncertainty in both and outputs an abstention response.
Key Novelty
Contrastive Decoding with Abstention (CDA)
- Introduces an explicit 'abstention' output distribution into the contrastive decoding equation
- Dynamically calculates weights for parametric, contextual, and abstention distributions based on entropy-based uncertainty estimates
- Increases the weight of the abstention distribution specifically when the model is uncertain about both its internal knowledge and the provided context
Architecture
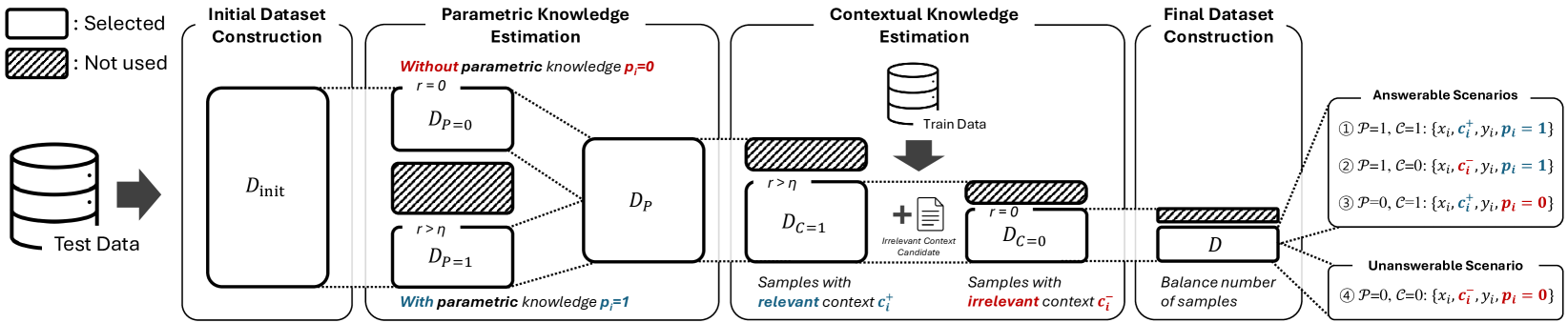
The overall workflow of Contrastive Decoding with Abstention (CDA), illustrating how weights are dynamically calculated and how distributions are combined.
Evaluation Highlights
- Achieves higher AUC (Area Under the Curve) scores for abstention decisions compared to self-consistency and logit-based baselines across NQ, HotpotQA, and TriviaQA
- Maintains or improves generation accuracy on answerable queries while effectively abstaining on unanswerable ones, outperforming standard CCD methods
- Demonstrates robustness across four different LLMs (Llama-3, Mistral, etc.) without requiring any model training or fine-tuning
Breakthrough Assessment
7/10
A clever, lightweight, training-free extension to contrastive decoding that solves a critical safety issue (abstention). High practical utility for RAG systems, though heavily reliant on the quality of uncertainty estimation.