📝 Paper Summary
Graph-based RAG pipeline
RPO-RAG improves small LLM reasoning on knowledge graphs by training them with relation-level preference signals derived from semantically sampled paths, rather than just final answer supervision.
Core Problem
Existing KG-based RAG methods rely on semantics-unaware shortest-path heuristics that introduce irrelevant noise, and they supervise models only on final answers, failing to teach small LLMs the intermediate reasoning steps required for complex queries.
Why it matters:
- Small LLMs (sub-7B) lack the capacity to filter irrelevant retrieval noise or organize fragmented evidence, leading to hallucinations
- Prior methods prioritize topological proximity over semantic relevance, causing models to learn incorrect reasoning patterns
- Current flat-list prompts do not guide models to integrate evidence from multiple paths into a coherent answer
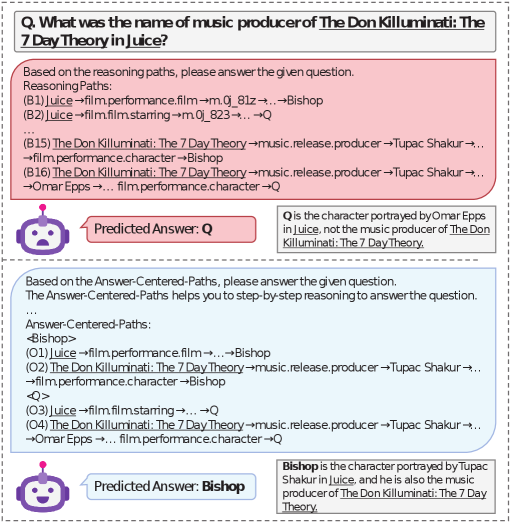
Concrete Example:
For the query 'Who is the character in Juice and music producer of The Don Killuminati?', standard methods retrieve paths like 'Juice -> character -> Q' because 'Q' is topologically close, ignoring the 'music producer' constraint. RPO-RAG identifies the path connecting both constraints ('Juice' and 'The Don Killuminati') to the correct answer 'Bishop'.
Key Novelty
Relation-aware Weighted Preference Optimization for RAG
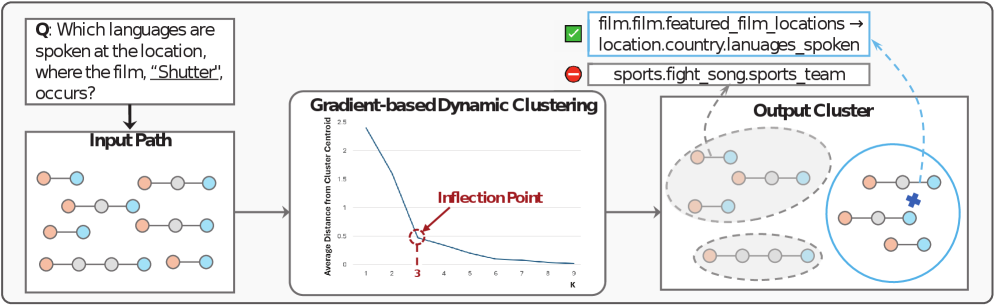
- Replaces heuristic path sampling (e.g., BFS) with a query-path semantic sampling strategy that clusters paths by embedding similarity to find those matching query intent
- Introduces a relation-level preference optimization objective that trains the LLM to prefer semantically relevant relations at each step of the reasoning path, rather than just the final answer
- Restructures prompts into an 'answer-centered' format that groups all reasoning paths supporting a specific candidate answer together, helping small LLMs aggregate evidence
Architecture
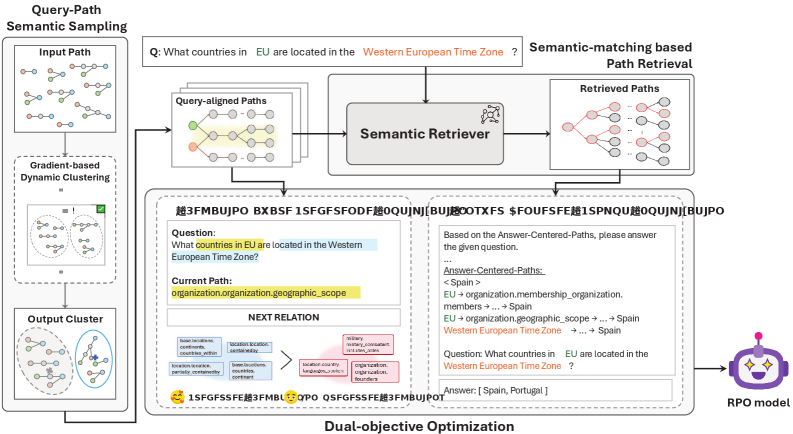
The overall architecture of RPO-RAG, illustrating the pipeline from query to answer.
Evaluation Highlights
- Achieves state-of-the-art results among sub-8B models on WebQSP (89.9 Hit) and CWQ datasets, surpassing the previous best (GCR) by +2.7% Hit and +10.2% F1 on WebQSP (Llama3.1-8B)
- RPO-RAG with Llama3.2-3B improves Hit by +24.8% on WebQSP and +46.1% on CWQ compared to the vanilla base model, showing effective capability transfer to small models
- Significantly closes the gap with large proprietary models: RPO-RAG (Llama3.2-1B) surpasses ToG (ChatGPT) by +6.1% Hit on WebQSP
Breakthrough Assessment
8/10
Strong empirical gains for small models, effectively enabling them to perform complex graph reasoning previously reserved for larger models. The relation-level optimization is a novel and logical extension of preference learning to KGQA.