📝 Paper Summary
Hallucination suppression
Knowledge internalization
LLMs often store correct factual knowledge in their parameters even when generating incorrect or 'unsure' answers, which can be recovered by inspecting top-ranked token probabilities.
Core Problem
Standard QA accuracy metrics underestimate LLM knowledge because models frequently output incorrect answers or 'unsure' responses even when the correct answer is present with high probability in the internal logit distribution.
Why it matters:
- Current prompting strategies that encourage models to say 'unsure' to reduce hallucinations inadvertently suppress valid knowledge expression
- Evaluating models solely on top-1 generation fails to capture the true extent of factual information encoded in parameters
- Deployment strategies relying on surface-level accuracy may falsely conclude a model lacks domain knowledge when it actually suffers from conservative decoding
Concrete Example:
When asked 'What is the capital of Washington?', a model might output 'Seattle' or 'unsure', yet the correct answer 'Olympia' appears as the second or third most probable token in the model's internal ranking.
Key Novelty
Hits@k for Latent Knowledge Evaluation & 'Unsure' Filtering
- Introduces a metric (Hits@k) that counts a model as 'knowing' a fact if the correct answer appears anywhere in the top-k most probable tokens, revealing latent memory
- Identifies a 'memory-masking effect' where safety prompts cause models to output 'unsure' despite having the correct answer as a high-probability candidate
- Proposes a decoding strategy that filters out uninformative tokens (like 'unsure') and forces the model to select the next best candidate, often recovering the correct fact
Architecture
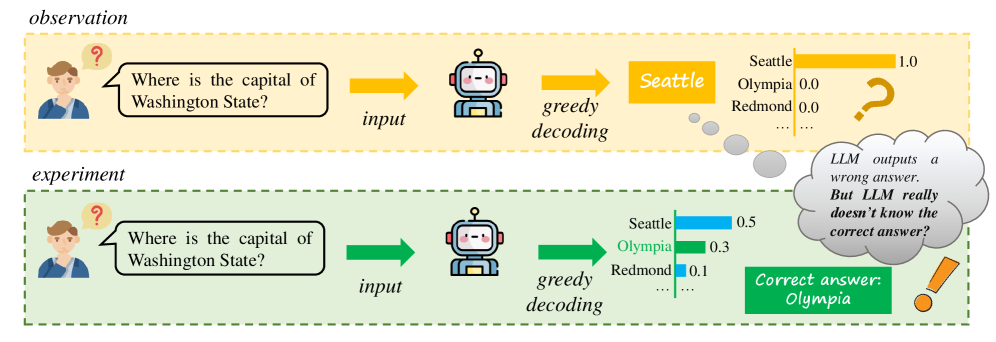
Conceptual illustration of the knowledge storage-expression gap. Shows a model outputting 'Seattle' (incorrect) for Washington's capital, while the correct answer 'Olympia' has high probability in the distribution.
Evaluation Highlights
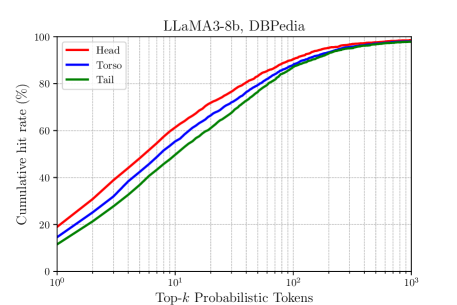
- On DBpedia, LLaMA3-8b achieves only 17.2% standard accuracy (Hits@1) but reaches 57.9% latent knowledge retention (Hits@5), a massive gap between expression and storage
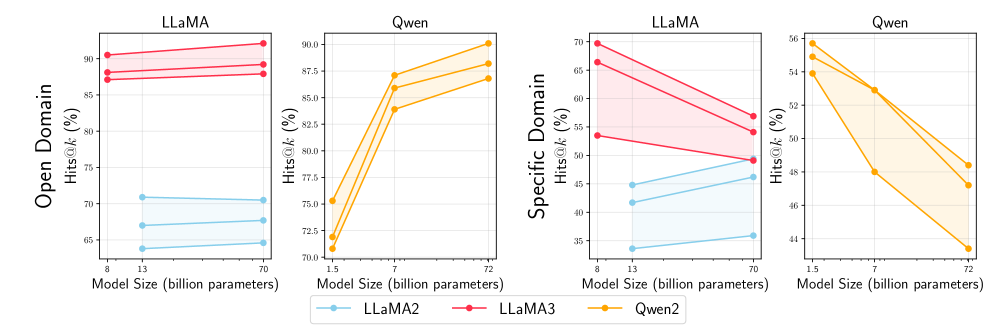
- Newer models like LLaMA3-70b reach 92.1% Hits@5 on DBpedia-head compared to 70.5% for LLaMA2-70b, showing improved knowledge encoding
- Filtering 'unsure' responses allows recovering significant portions of correct answers; effectively transforming 'unsure' outputs into correct predictions
Breakthrough Assessment
7/10
Provides strong empirical evidence of the storage-expression gap and challenges the standard practice of encouraging 'unsure' responses without checking latent confidence.