📝 Paper Summary
Vision-Language Benchmarks
Image Captioning Evaluation
Hallucination Detection
CompreCap is a benchmark for evaluating detailed image captions using manually annotated directed scene graphs that bind attributes to objects and define directional relationships, improving upon isolated word matching.
Core Problem
Existing captioning benchmarks (like MSCOCO) use brief captions that fail to evaluate the comprehensive details generated by modern Large Vision-Language Models (LVLMs), while current detailed benchmarks treat objects, attributes, and relations as isolated words.
Why it matters:
- Brief captions (avg ~10 words) cannot assess the rich visual information LVLMs are capable of generating
- Current evaluation methods like DetailCaps parse isolated words, meaning a model can assign the wrong color to an object or reverse a relationship (e.g., 'A left of B' vs 'B left of A') and still get a high score
- Hallucination benchmarks (POPE, FGHE) focus only on object existence, ignoring attribute descriptions and relationships
Concrete Example:
If an image shows a 'red car' and a 'blue truck', a caption saying 'blue car and red truck' would score highly on bag-of-words metrics because all the correct words exist, despite the attributes being mismatched. CompreCap fixes this by evaluating the structural binding of attributes to specific objects.
Key Novelty
Directed Scene Graph Evaluation for Detailed Captions
- Constructs a directed scene graph where attributes are explicitly bound to objects and relationships are directional (subject-verb-object)
- Evaluates generated captions by decomposing them into sub-captions and matching them hierarchically against the ground-truth scene graph using an LLM evaluator
- Includes a specialized Visual Question Answering (VQA) task for 'tiny objects' (<5% image area) to test fine-grained perception
Architecture

The evaluation pipeline showing how a generated caption is parsed and matched against the ground-truth scene graph.
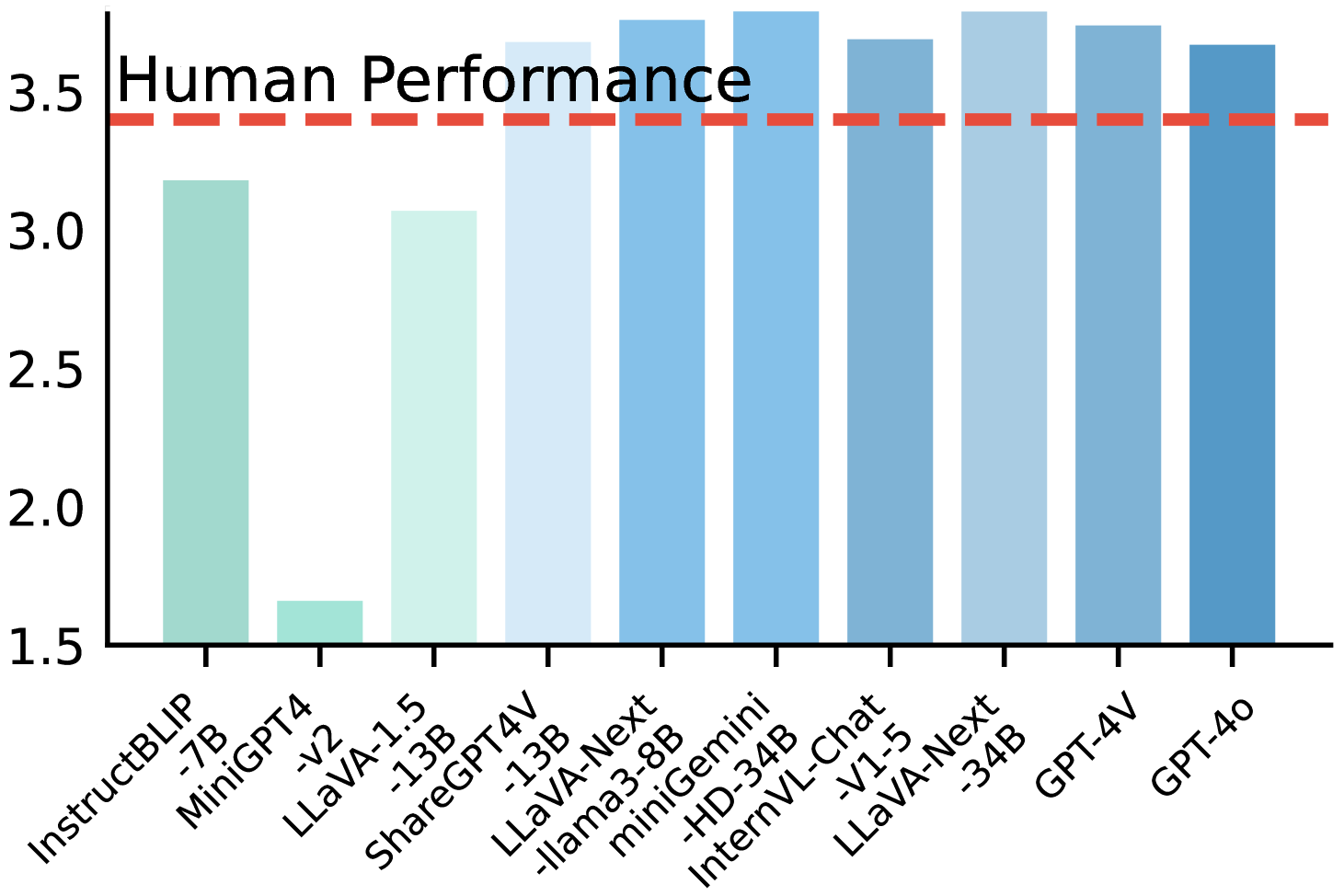
Evaluation Highlights
- Human performance significantly outperforms all 10 evaluated LVLMs (62.99 unified score vs 60.05 for GPT-4o), validating the benchmark's difficulty
- LLaVA-Next-34B achieves the highest unified score among models (58.85), slightly outperforming GPT-4o (60.05) on object/attribute metrics but lagging in relationships
- Proposed metric achieves strong consistency with human judgment compared to traditional metrics like SPICE or CLIPScore
Breakthrough Assessment
8/10
Addresses a critical gap in evaluating modern LVLMs (detailed captioning) with a rigorous, structure-aware methodology. The use of directed scene graphs to prevent attribute-swapping errors is a significant methodological improvement.