📝 Paper Summary
Modularized RAG pipeline
Hallucination suppression
QuCo-RAG determines when to retrieve by checking if entities in the question or generated answer are rare or non-co-occurring in the pre-training corpus, replacing unreliable model confidence scores with objective statistical evidence.
Core Problem
Existing dynamic RAG methods rely on internal model signals (logits, entropy) to detect hallucinations, but these are unreliable because LLMs are often ill-calibrated and confidently wrong.
Why it matters:
- LLMs frequently exhibit 'confident hallucinations,' assigning high probability to factually incorrect statements, which fools entropy-based detectors
- Theoretical work suggests even perfectly calibrated models must hallucinate on rare facts to maintain statistical consistency
- Current methods like DRAGIN fail to trigger retrieval for obvious errors (e.g., wrong names) while flagging safe tokens, wasting compute on unnecessary searches
Concrete Example:
When generating the director of a movie, the baseline DRAGIN assigns low uncertainty (high confidence) to the incorrect name 'Mario Camerini', failing to trigger retrieval. Conversely, it assigns high uncertainty to the common word 'Il' in the question, triggering useless retrieval. QuCo-RAG detects that 'Mario Camerini' never co-occurs with the movie title in the pre-training corpus, correctly flagging the error.
Key Novelty
Corpus-Grounded Uncertainty Quantification
- Shifts uncertainty estimation from subjective internal model states (logits/entropy) to objective external statistics derived directly from the pre-training corpus
- Uses two specific statistical signals: low-frequency entities in the question (indicating input ignorance) and zero co-occurrence between entities in the generated answer (indicating lack of evidential support)
- Leverages efficient suffix-array infrastructure (Infini-gram) to query these statistics from trillion-token corpora in milliseconds during inference
Architecture
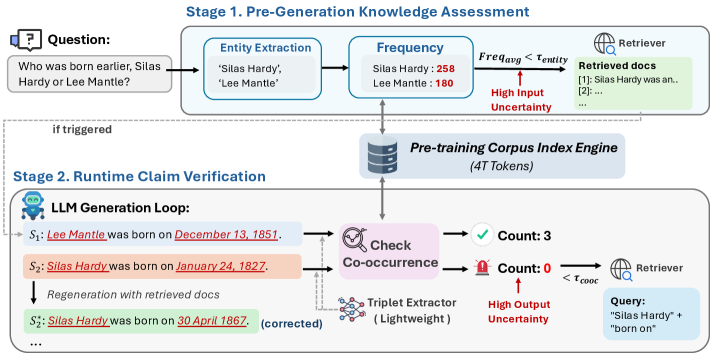
The QuCo-RAG inference pipeline illustrating the two-stage uncertainty quantification process.
Evaluation Highlights
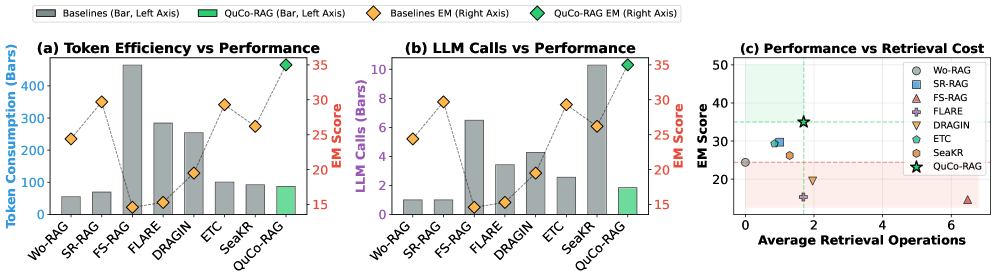
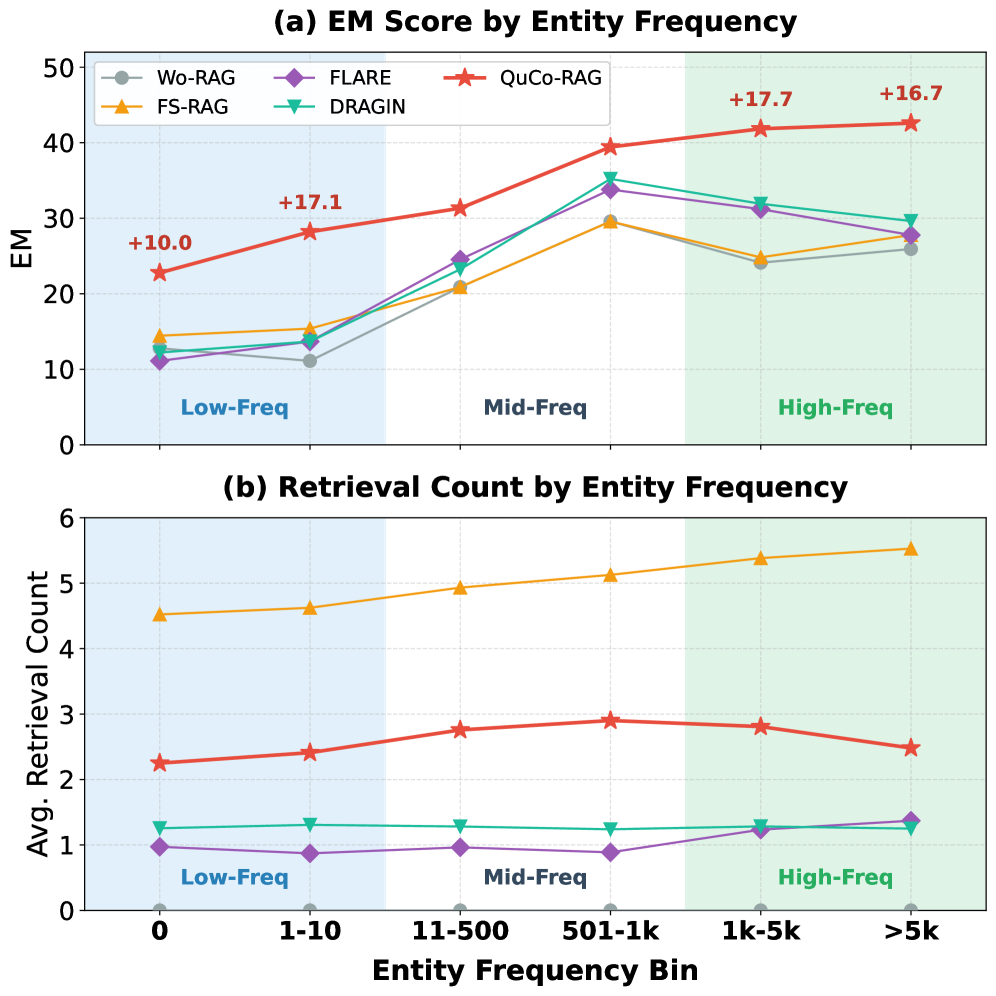
- +5.4 to +12.0 Exact Match (EM) improvement over state-of-the-art baselines (SeaKR, ETC, DRAGIN) on OLMo-2 models across HotpotQA and 2WikiMultihopQA
- Achieves +14.1 EM gain on 2WikiMultihopQA with Qwen2.5-32B by using OLMo-2's corpus as a proxy, demonstrating strong cross-model transferability
- Outperforms GPT-5-chat's built-in web search by +5.5 to +8.7 EM points, proving that precise statistical verification beats generic agentic search for specific fact retrieval
Breakthrough Assessment
9/10
Establishes a new paradigm for dynamic RAG by grounding decisions in objective corpus data rather than unreliable model logits. The cross-model transferability (using one model's corpus to check another) is a highly practical and significant finding.