📝 Paper Summary
Visual Document Retrieval (VDR)
Vision-Language Models (VLMs)
MURE improves document retrieval by encoding images at multiple resolutions using Matryoshka learning for feature fusion and hierarchical clustering for efficient token compression.
Core Problem
Existing VDR models struggle to balance detail and efficiency: fixed-resolution models lose fine-grained visual cues, while native-resolution models generate excessive tokens, causing high storage and latency costs.
Why it matters:
- High-resolution documents (e.g., maps, charts) require fine-grained perception that standard 336x336 encoding misses.
- Excessive visual tokens in native-resolution approaches (like ColPali) explode index sizes, making large-scale retrieval computationally prohibitive.
- Current methods fail to simultaneously capture high-level layout structure and low-level text details within a unified efficient representation.
Concrete Example:
When answering 'What is the background color of the US on the map?', a model needs a coarse global view. For 'Which color represents countries in the legend?', it needs a fine-grained view. Single-resolution models typically fail at one of these, either missing the legend details or losing the global map context.
Key Novelty
X-VisEmb Paradigm (Multi-Resolution Encoding with Adaptive Distillation)
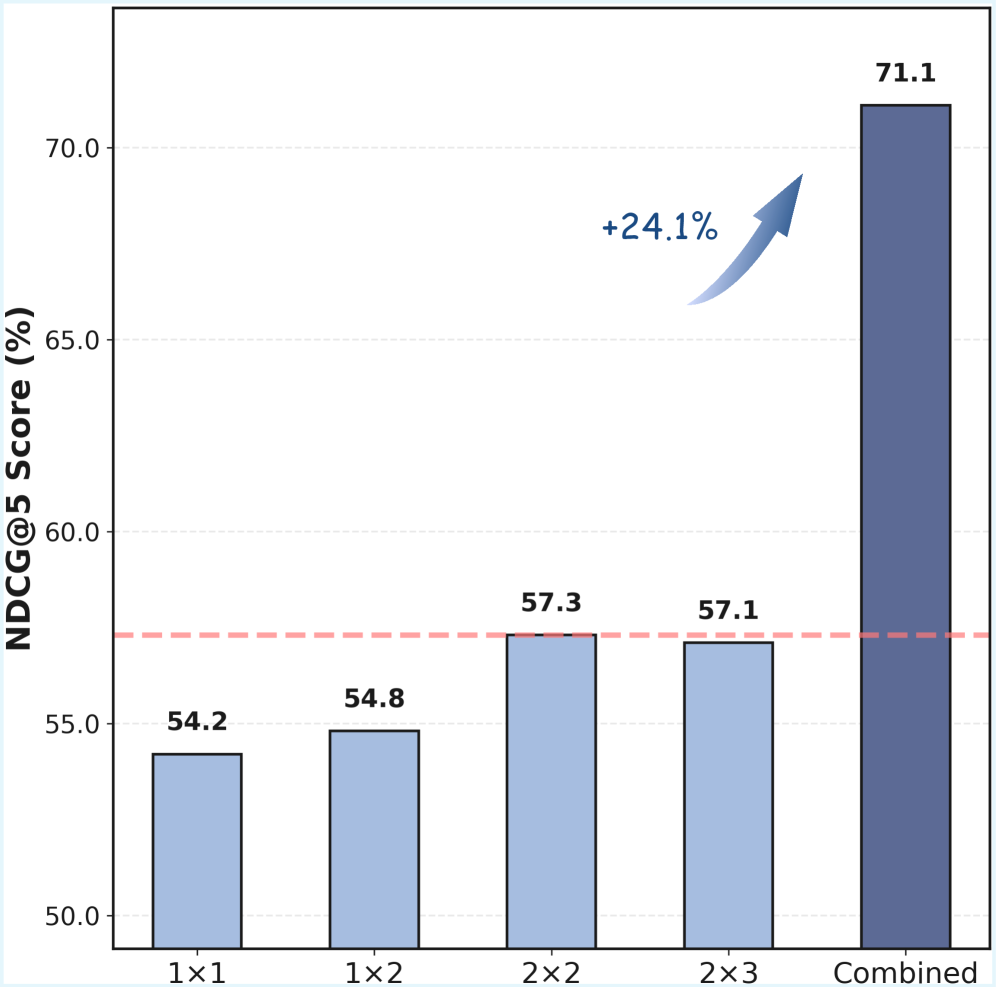
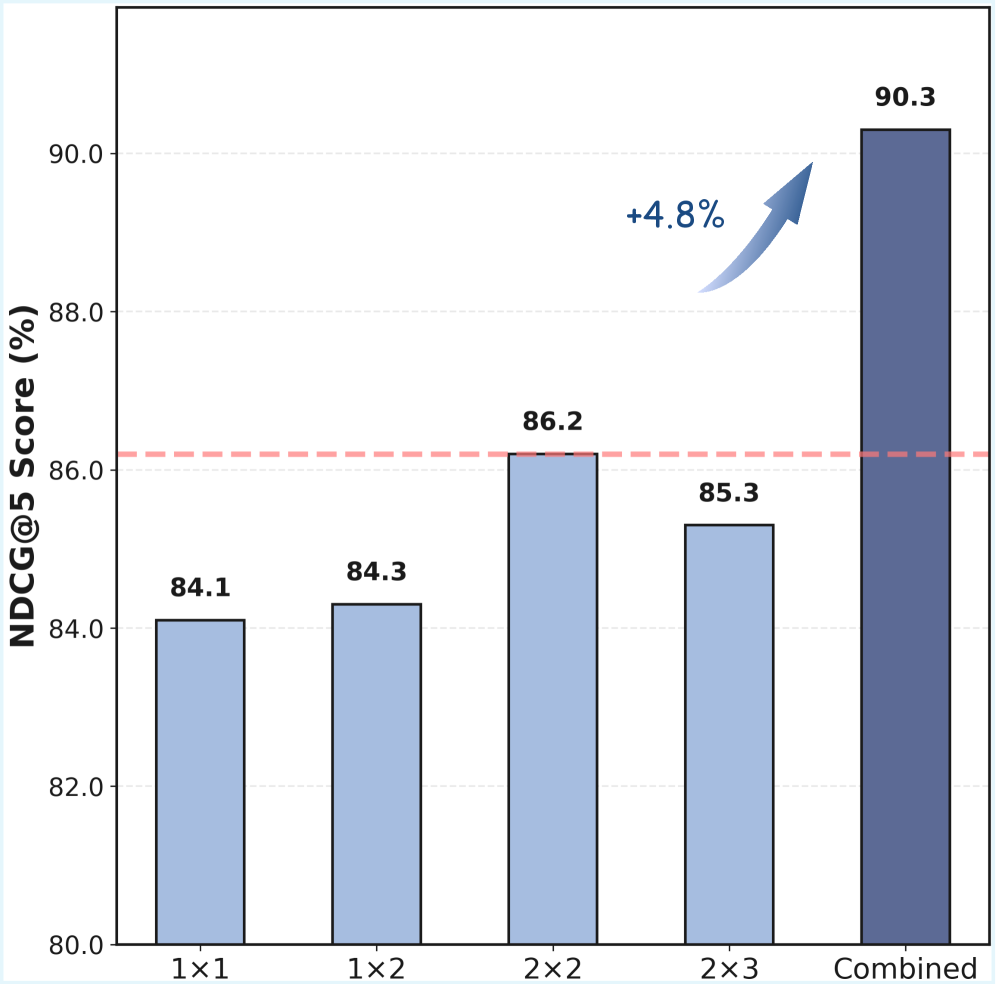
- Applies an 'optical zoom' strategy by resizing document images into a hierarchy of grids (1x1 to 2x3) to capture both global structure and local details.
- Uses Resolution-level Matryoshka Representation Learning (RMRL) to nest features, allowing the model to prioritize coarse features while progressively adding fine details.
- Employes semantic-aware hierarchical clustering during indexing to compress redundant visual tokens into a fixed budget without retraining.
Architecture
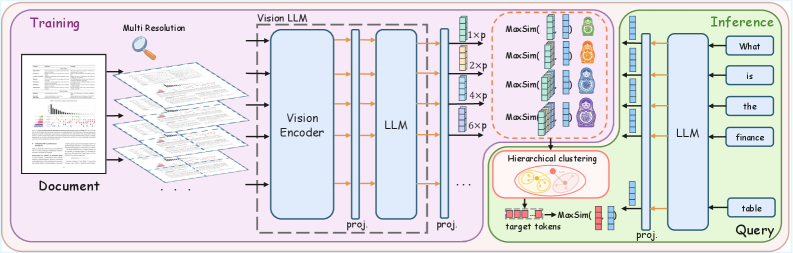
The inference pipeline of MURE, illustrating how a document is processed from image to compressed embedding.
Evaluation Highlights
- Outperforms ColMate by +1.9% (ViDoRe V1) and +2.3% (ViDoRe V2) in NDCG@5, setting a new SOTA for PaliGemma-based retrievers.
- Surpasses the full-resource ColPali model using only 512 visual tokens (50% of ColPali's budget) on both benchmarks.
- Maintains 95.2% of full performance on ViDoRe V1 even when compressed to just 128 tokens, demonstrating extreme storage efficiency.
Breakthrough Assessment
8/10
Successfully addresses the critical efficiency-granularity trade-off in VDR. The ability to beat SOTA with 50% fewer tokens is a significant practical advantage for deployment.