📝 Paper Summary
Graph-based RAG pipeline
KG-Retriever builds a hierarchical index graph combining a collaborative document layer with an entity-level knowledge graph to enable comprehensive, single-step retrieval for multi-hop QA tasks.
Core Problem
Existing RAG methods struggle with complex multi-hop questions that require navigating fragmented information across multiple documents, often necessitating computationally expensive iterative retrieval steps.
Why it matters:
- Standard RAG systems fail to reason over different documents, leading to incomplete answers for complex queries
- Iterative retrieval methods (like ITRG or IRCOT) improve reasoning but incur escalating computational costs due to repeated retrieval and generation cycles
- Disjoint retrieval steps in iterative methods can fail to effectively integrate information across documents
Concrete Example:
For the question 'What are the trend and major factors contributing to dry eye syndrome...?', standard RAG might retrieve only one document about symptoms, missing preventive measures located in a separate, indirectly related document.
Key Novelty
Hierarchical Index Graph (HIG) for Single-Step Deep Retrieval
- Constructs a dual-layer graph: a 'collaborative document layer' connecting documents by semantic similarity, and a 'knowledge graph layer' modeling intra-document entities
- Uses a two-stage retrieval process: first expanding candidate documents via graph neighbors (document collaboration), then filtering specific entity triples (KG-level retrieval) to refine context
Architecture
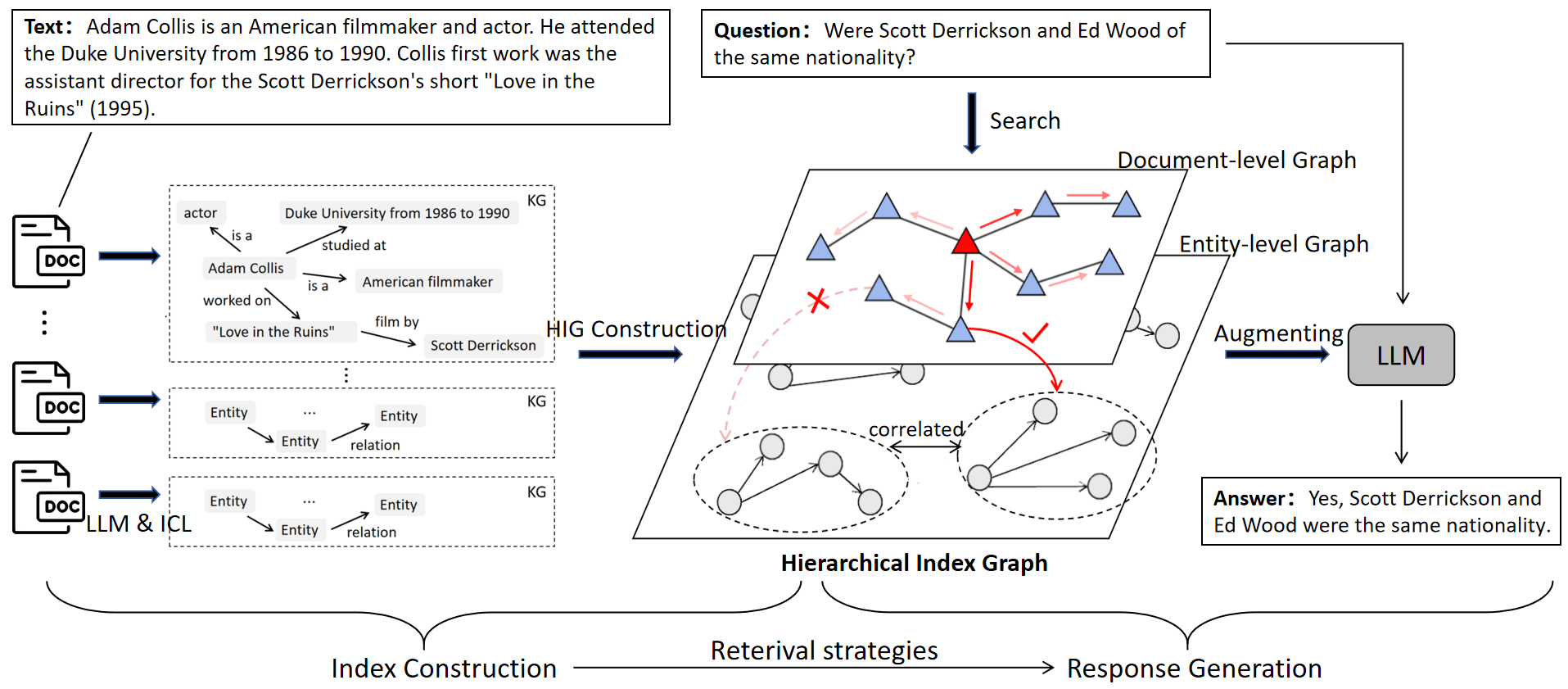
Overview of the KG-Retriever framework illustrating the Hierarchical Index Graph (HIG) construction and the retrieval process.
Evaluation Highlights
- Achieves State-of-the-Art performance on 5 QA datasets (HotpotQA, MuSiQue, 2WikiMultilHopQA, CRUD-QA1/2) compared to iterative baselines
- 6 to 15 times faster inference speed than iterative methods like ITRG (11.6x) and ITER-RETGEN (8.4x) due to its single-step retrieval design
- Outperforms retrieval-augmented baselines in Exact Match (EM) scores; e.g., higher EM on HotpotQA compared to Graph-guided reasoning and dense retrieval methods
Breakthrough Assessment
8/10
Significantly improves efficiency (speed) while maintaining or beating SOTA accuracy on complex QA tasks by replacing iterative retrieval with a structured hierarchical index.