📝 Paper Summary
Test-Time Scaling (TTS)
Video Generation
Diffusion Models
Video-T1 enhances video generation quality without retraining by treating inference as a search problem, utilizing a Tree-of-Frames algorithm to adaptively explore and verify trajectories from noise to video.
Core Problem
Generating high-quality, temporally coherent videos is computationally expensive and difficult to scale via training alone; standard inference methods do not leverage additional compute to correct errors or improve alignment.
Why it matters:
- Scaling video models via pre-training requires massive data and compute resources, hitting diminishing returns
- Existing video diffusion models struggle with complex dynamics and long-term temporal coherence when generating from simple noise samples without guidance
- Current inference methods lack the 'reasoning' capabilities seen in LLMs (like OpenAI o1) to refine outputs during test-time
Concrete Example:
In standard generation, a model might generate a video where a subject changes appearance halfway through. Without test-time scaling, the model cannot 'look ahead' or 'backtrack' to correct this inconsistency, whereas Video-T1's verifiers would prune such a trajectory.
Key Novelty
Video Generation as a Search Problem (Video-T1)
- Reinterprets the video diffusion process as finding an optimal path through a 'degenerate tree' of noise-to-frame transitions
- Introduces 'Tree-of-Frames' (ToF), an autoregressive search algorithm that breaks generation into stages (initial, intermediate, final) and uses heuristics to prune poor branches based on verifier feedback
- Applies hierarchical prompting where verifiers evaluate different criteria (e.g., spatial layout vs. motion smoothness) depending on the generation stage
Architecture
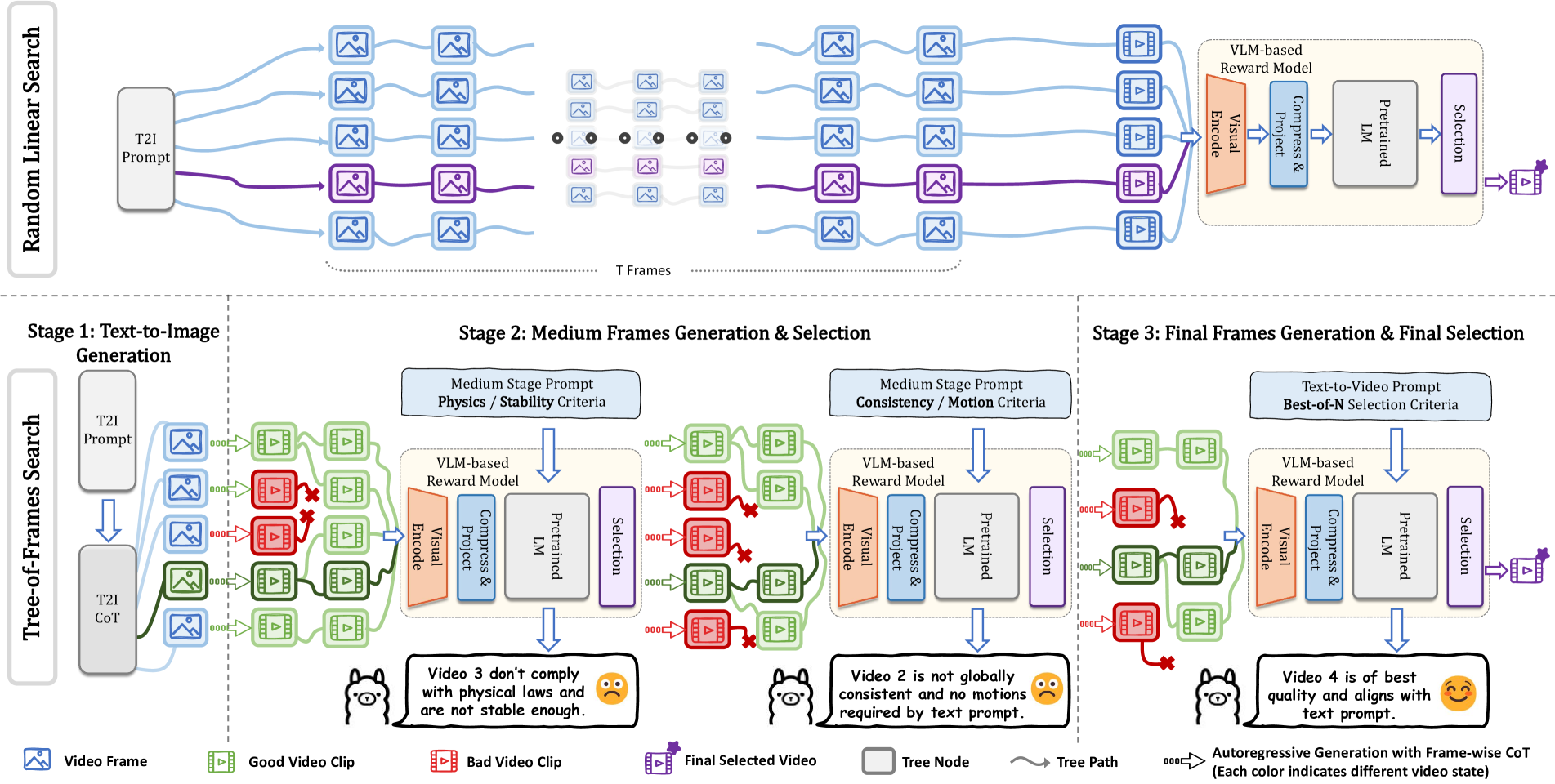
Comparison of Random Linear Search vs. Tree-of-Frames (ToF) Search strategies.
Evaluation Highlights
- Quantitative results are not reported in the provided text fragment (text ends at Section 3.3).
- Qualitative claim: Increasing test-time compute consistently leads to significant improvements in video quality and human-preference alignment.
- Qualitative claim: Tree-of-Frames (ToF) search significantly reduces scaling cost compared to random linear search while achieving high-quality results.
Breakthrough Assessment
8/10
Novel application of Test-Time Scaling (proven in LLMs) to the video domain. The Tree-of-Frames approach addresses the specific temporal constraints of video, offering a potential efficiency breakthrough over brute-force Best-of-N.