📝 Paper Summary
Test-Time Scaling (TTS)
Reasoning
Process Reward Models (PRMs)
By integrating reward signals into compute-optimal scaling strategies and using absolute difficulty thresholds, significantly smaller models (e.g., 3B) can outperform massive models (e.g., 405B) on complex reasoning tasks.
Core Problem
Current Test-Time Scaling (TTS) methods lack systematic analysis of how policy models, Process Reward Models (PRMs), and problem difficulty interact, often using ineffective difficulty metrics (quantiles) and ignoring reward influence during optimization.
Why it matters:
- Blindly scaling compute at test time is inefficient if the search strategy doesn't adapt to the specific model's capability and the problem's hardness
- Existing approaches often rely on offline PRMs that suffer from distribution shift, leading to sub-optimal compute allocation
- Understanding these dynamics allows smaller, more efficient models to match or beat state-of-the-art closed-source models (like o1) without massive pre-training costs
Concrete Example:
When using Llama-3.1-8B with a PRM trained on Mistral (RLHFlow-Mistral), the PRM erroneously assigns high rewards to short, incorrect responses due to distribution shift. A standard TTS strategy might select these short answers, whereas a 'reward-aware' strategy would adjust the search budget or method to account for this bias.
Key Novelty
Reward-Aware Compute-Optimal Test-Time Scaling
- Formulates the scaling strategy optimization to explicitly condition on the reward function (PRM), not just the policy model and compute budget
- Replaces relative difficulty metrics (quantiles) with absolute accuracy thresholds to better categorize problems across models with vastly different baseline capabilities
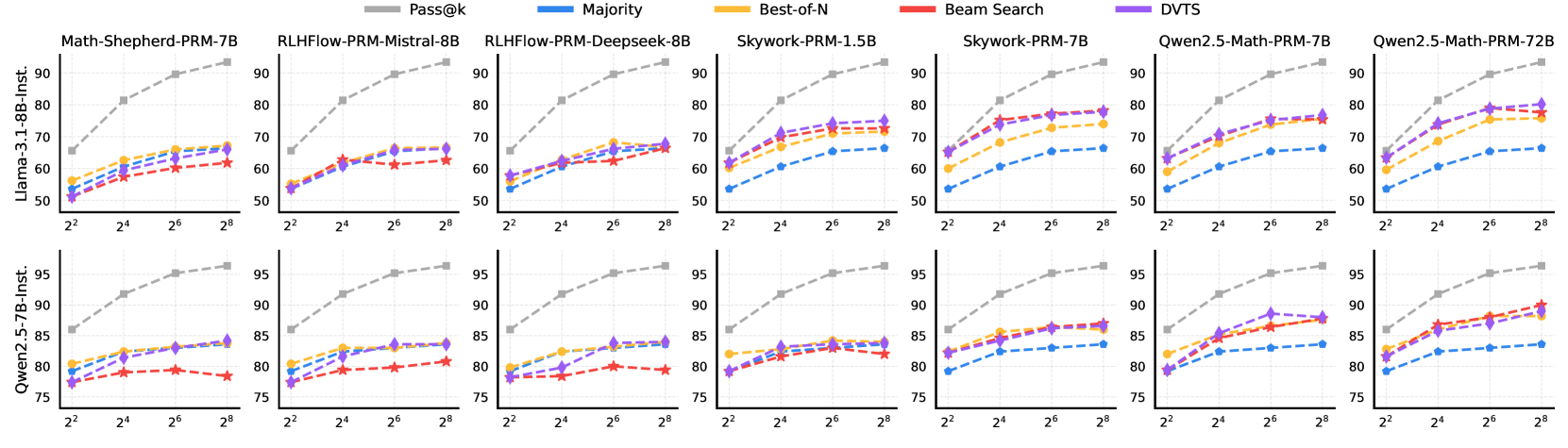
- Demonstrates that the optimal search method (Best-of-N vs. Beam Search vs. Tree Search) flips depending on model size: small models need step-by-step verification, while large models often do better with simple sampling
Architecture
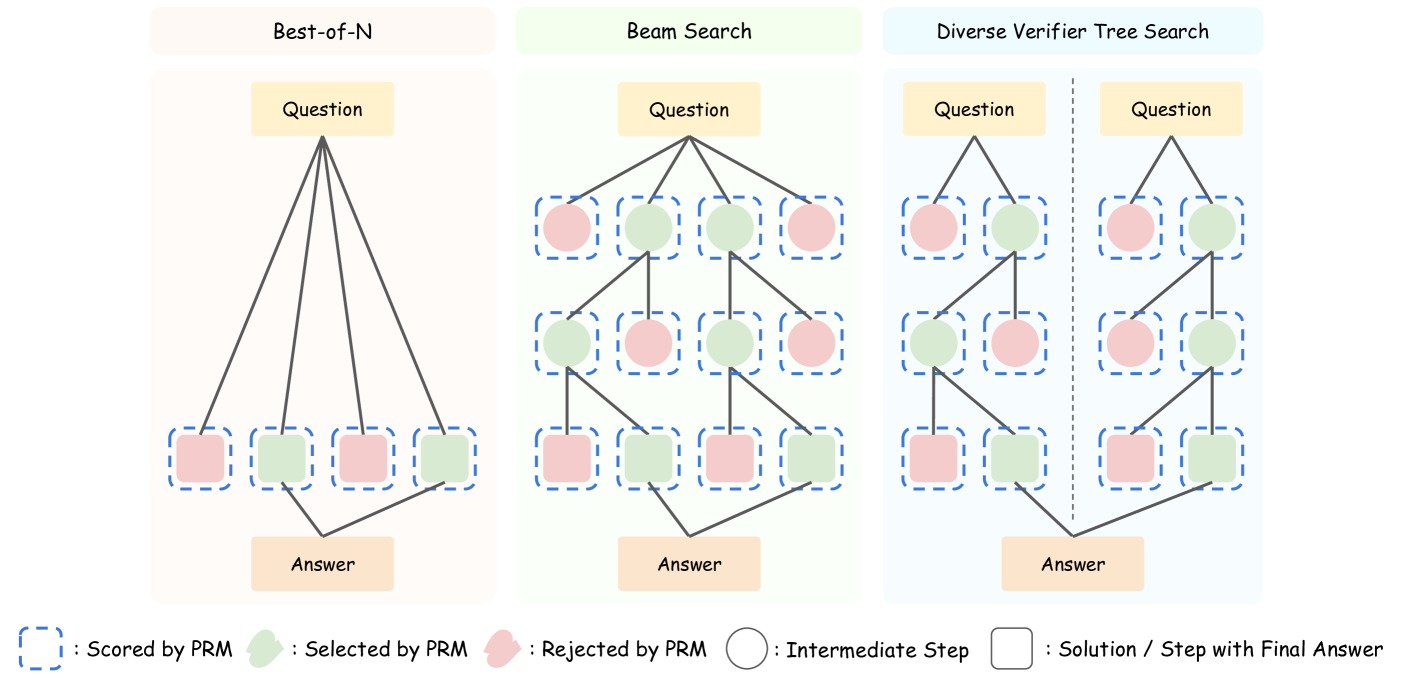
Schematic of the three Test-Time Scaling (TTS) methods evaluated: Best-of-N, Beam Search, and Diverse Verifier Tree Search (DVTS).
Evaluation Highlights
- A 3B parameter model (Qwen2.5-Math) surpasses a 405B parameter model (Llama-3.1) on the MATH-500 benchmark using the proposed compute-optimal TTS
- A 7B model outperforms both OpenAI o1 and DeepSeek-R1 on MATH-500 and AIME24 tasks while maintaining higher inference efficiency
- A 1B model surpasses a 405B model on MATH-500 when using the optimal combination of Policy, PRM, and search strategy
Breakthrough Assessment
8/10
Strong empirical evidence challenging the 'bigger is better' dogma by showing massive efficiency gains via intelligent inference scaling. systematically analyzes the interaction between PRMs and Policies.