📝 Paper Summary
Language Model Pre-training
Data Efficiency
Steerability/Control
MeCo accelerates pre-training by conditioning models on document metadata (like URLs) during the majority of training, followed by a brief cooldown on standard data to ensure robust unconditional performance.
Core Problem
Standard language models treat all pre-training documents as equivalent, ignoring crucial source context (e.g., distinguishing a meme from a biography) and impeding reliable behavior steering.
Why it matters:
- LMs struggle to distinguish quality or intent across heterogeneous web sources without explicit signals
- Standard training requires massive amounts of data; improving data efficiency is critical for scaling
- Current models are hard to steer towards specific behaviors (e.g., factuality vs. humor) without extensive fine-tuning
Concrete Example:
Documents about Apple CEO Tim Cook range from memes ('Tim doesn't cook anymore') to biographies. Without metadata, a model treats these as identical factual claims. MeCo uses source URLs to help the model distinguish a meme site from a financial report.
Key Novelty
Metadata Conditioning then Cooldown (MeCo)
- Prepend metadata (e.g., 'URL: en.wikipedia.org') to text during the first 90% of pre-training so the model learns to associate content with its source
- Switch to standard, unconditional training for the final 10% (cooldown) to ensure the model can still function normally without metadata prompts
- Use metadata cues during inference (conditional inference) to steer model behavior, such as reducing toxicity or improving factuality
Architecture

Illustration of the MeCo training process and inference steering
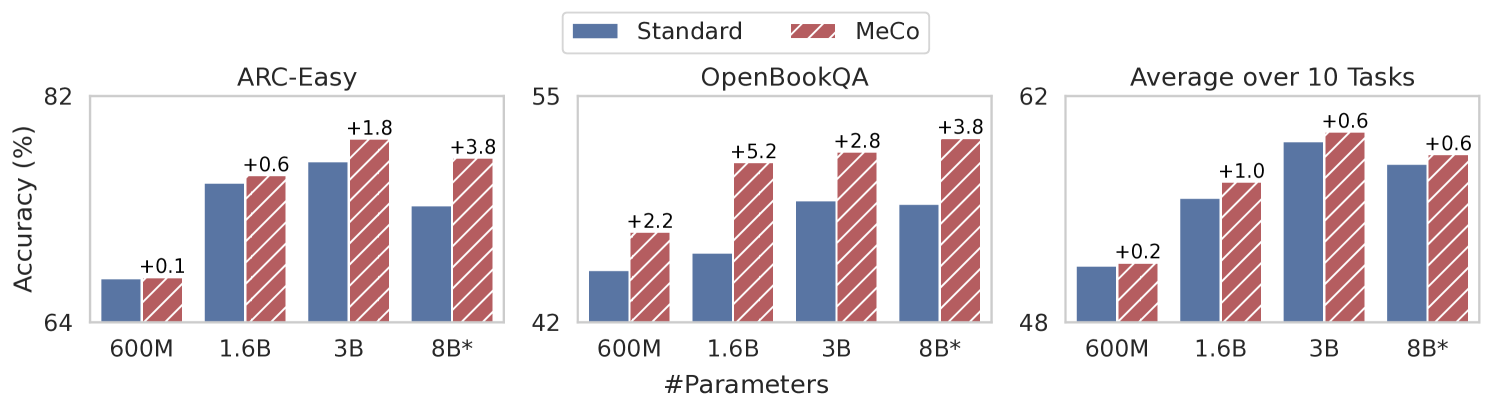
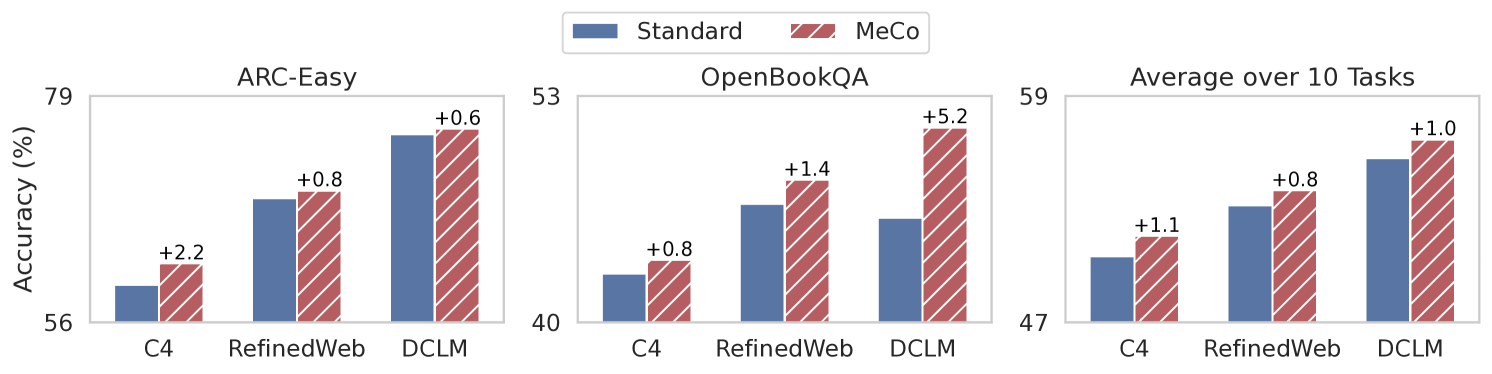
Evaluation Highlights
- Matches standard 1.6B model performance using 33% less training data (160B vs 240B tokens)
- +1.5% absolute average improvement on downstream tasks when using conditional inference compared to standard unconditional models
- Reduces toxicity significantly when conditioned on 'wikipedia.org' compared to standard unconditional inference
Breakthrough Assessment
8/10
Simple, compute-neutral method that significantly improves data efficiency (33% savings) and adds steering capabilities. Applicable to any web-scale pre-training.