📝 Paper Summary
Prompt Optimization
Automated Prompt Engineering
Small Language Models (SLMs)
GReaTer optimizes prompts for smaller language models by using numerical loss gradients over generated reasoning chains, enabling self-improvement without relying on expensive feedback from larger models.
Core Problem
Existing prompt optimization methods rely on textual feedback from massive, expensive LLMs (like GPT-4) because smaller models cannot generate high-quality feedback, creating a dependency loop.
Why it matters:
- Smaller models (e.g., Llama-3-8B) struggle to self-optimize using text-based critiques, limiting their standalone utility
- Reliance on proprietary models (GPT-4) for optimization increases cost and privacy concerns
- Current methods operate purely in text space, ignoring fine-grained gradient information that could guide better token selection
Concrete Example:
A small model solving a math problem might fail. Current methods ask GPT-4 to explain why and suggest a new prompt. GReaTer instead calculates the actual gradient of the loss with respect to the prompt tokens *through* the reasoning steps, mathematically determining which words to change.
Key Novelty
Gradient-over-Reasoning Prompt Optimization
- Proposes prompt token candidates using the model's own forward probabilities rather than external suggestions
- Differentiates through the reasoning chain: calculates loss gradients based on how the prompt influences the generated reasoning and final answer
- Updates discrete prompt tokens by selecting candidates with the highest negative gradient (steepest descent direction), effectively treating prompts as optimizable parameters
Architecture
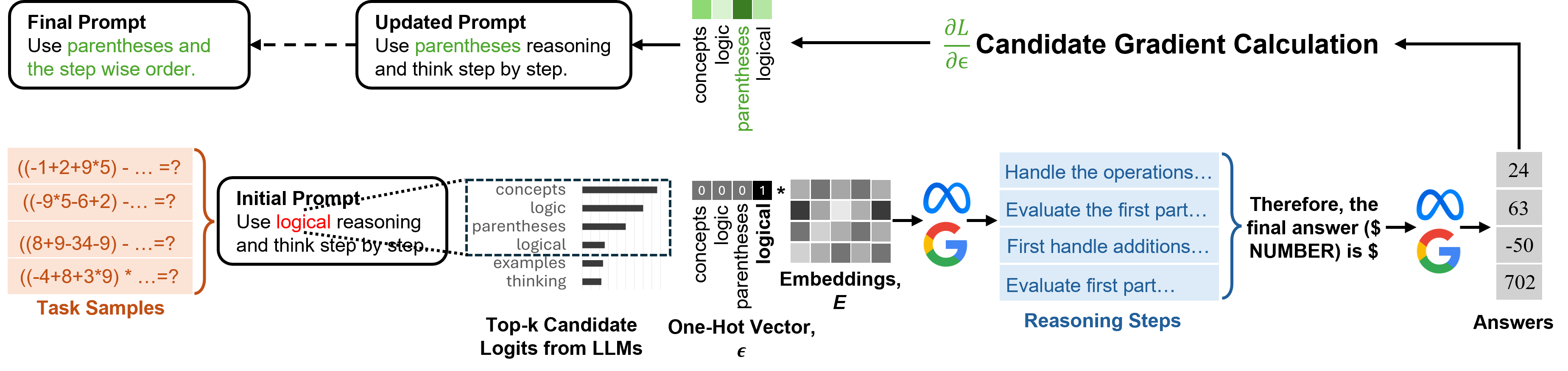
The 4-stage optimization pipeline: (1) Candidate Proposal, (2) Reasoning Generation, (3) Logit Extraction, and (4) Gradient-based Selection.
Evaluation Highlights
- Outperforms SOTA method TextGrad by +3.7% on BBH using Llama-3-8B-Instruct
- Achieves parity with or exceeds GPT-4 optimized prompts while using only open-source models (Llama-3-8B, Gemma-2-9B)
- Shows consistent gains across diverse tasks: +2.3% on GSM8K and +6.4% on FOLIO with Llama-3-8B compared to PE2
Breakthrough Assessment
8/10
Significant step towards making small models self-sufficient. By enabling gradient-based optimization over reasoning chains, it removes the critical dependency on closed-source giants for prompt engineering.