📝 Paper Summary
Multi-modal Large Language Models (MLLMs)
Speech-Language Models
Omni-modal Models
Lyra is an efficient omni-modal model that integrates vision, language, and long speech by leveraging latent cross-modality regularization and token extraction to handle extensive audio contexts.
Core Problem
Current Multi-modal LLMs (MLLMs) struggle to integrate speech with other modalities (like vision) and handle long speech inputs efficiently due to high computational costs and limitations in speech encoders.
Why it matters:
- Most omni-models focus only on speech-text relations, neglecting speech-vision connections essential for true omni-cognition
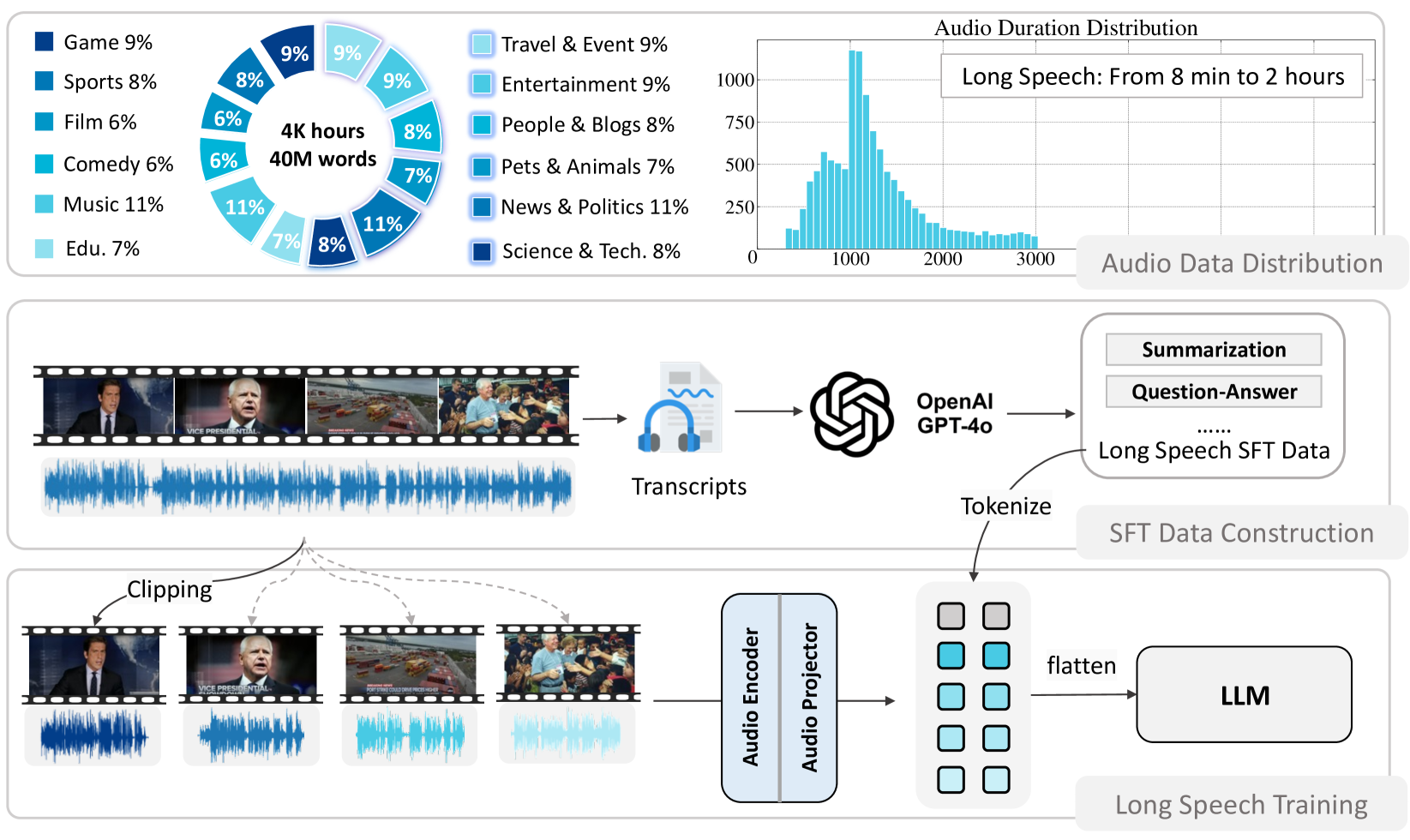
- Existing speech encoders (e.g., Whisper) produce excessive tokens for long audio (e.g., 360k tokens for 2 hours), overwhelming standard LLM context windows
- Training omni-models from scratch requires massive datasets and compute, raising environmental and financial concerns
Concrete Example:
A standard Whisper-v3 encoder generates 1,500 tokens for just 30 seconds of audio. For a two-hour speech, this results in 360,000 tokens, which exceeds the processing capacity of most LLMs, making long-speech understanding impossible without compression.
Key Novelty
Speech-Centric Latent Regularization and Extraction
- Latent Cross-Modality Regularizer (LCMR): Forces speech tokens to be geometrically close to their corresponding text transcript tokens in the latent space, improving alignment without full transcription
- Latent Multi-Modality Extractor: Dynamically discards redundant speech and vision tokens based on their attention similarity to the text query at specific network blocks, mimicking neural pruning
- Multi-Modality LoRA: Efficiently fine-tunes a pre-trained LLM on multiple modalities simultaneously using low-rank adapters, preserving original capabilities while adding speech skills
Architecture
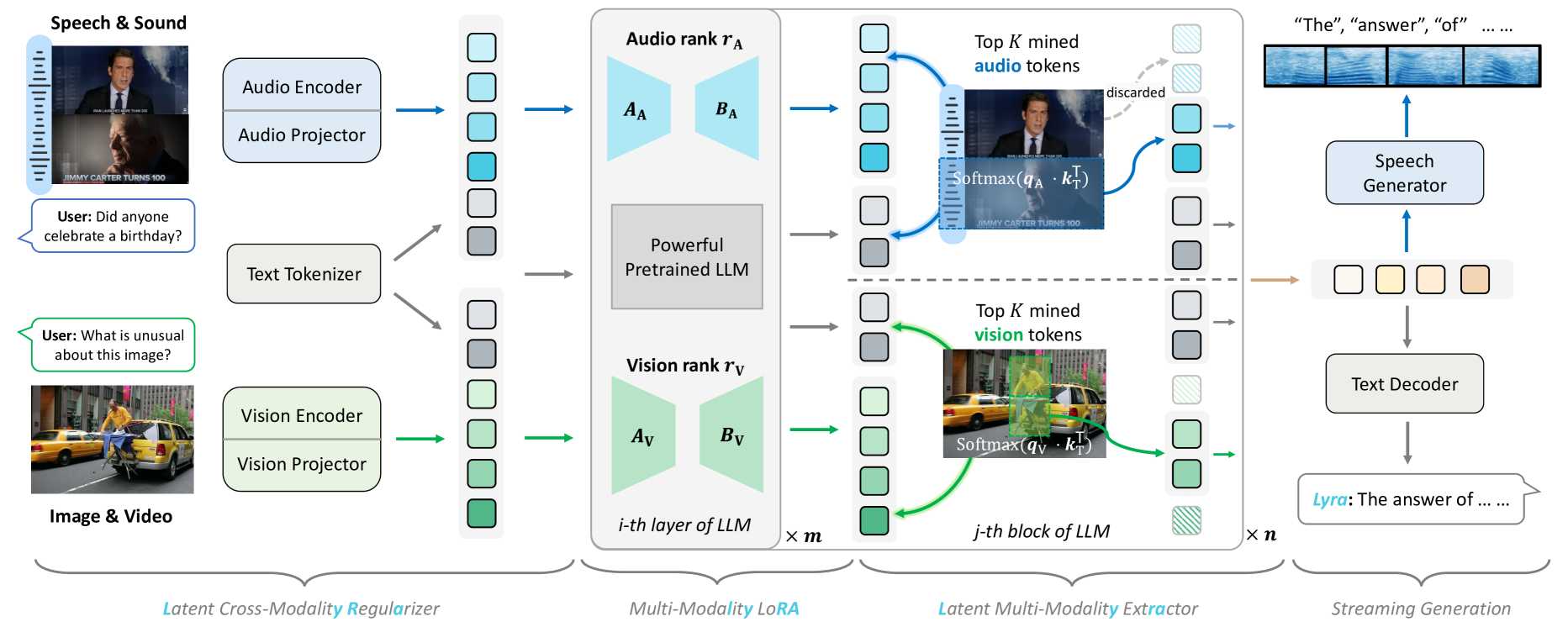
The overall architecture of Lyra, illustrating the four main components: latent cross-modality regularizer, multi-modality LoRA, latent multi-modality extractor, and streaming generation.
Evaluation Highlights
- Achieves state-of-the-art performance on various vision-language, vision-speech, and speech-language benchmarks compared to other omni-methods
- Successfully processes long speech inputs (up to several hours) using a compressed token representation (300 tokens per segment)
- Reduces training and inference computational costs through token reduction while maintaining performance
Breakthrough Assessment
8/10
Significant progress in efficient long-speech handling within MLLMs. The token compression and latent regularization strategies effectively address the bottleneck of processing hours-long audio, a major gap in current omni-models.