📝 Paper Summary
Audio-Language Models
Multimodal Learning
LTU-AS couples a frozen Whisper encoder with a LLaMA LLM via a Time-Layer-Wise Transformer, enabling a single model to simultaneously perceive and reason about both spoken text and non-speech background sounds.
Core Problem
Existing models typically specialize in either speech recognition (ASR) or audio event detection, lacking the reasoning capability to understand the interrelationship between speech content and environmental sounds (e.g., a car horn and a shout).
Why it matters:
- Real-world audio environments are multifarious, containing both speech and non-speech elements that require integrated interpretation for situational awareness
- Current audio-LLMs often ignore paralinguistic features (emotion, pitch) or fail to process background events while transcribing speech
- There is a lack of datasets combining speech and audio events for joint reasoning supervision
Concrete Example:
When hearing 'watch out!' and a car horn simultaneously, humans infer danger. Separate models might just transcribe the text or identify the horn, missing the causal link. LTU-AS can answer 'Why is the atmosphere tense?' by combining the semantic meaning of the shout with the acoustic event.
Key Novelty
LTU-AS (Listen, Think, Understand Audio and Speech)
- Dual-path perception: Uses Whisper to extract both discrete spoken text (via decoder) and continuous audio/paralinguistic tokens (via encoder + TLTR), feeding both to the LLM
- Time and Layer-Wise Transformer (TLTR) adapter: Applies attention across Whisper's encoder layers to capture 'soft' audio events and paralinguistic info that might be lost in the final layer
- Open-ASQA Dataset: A constructed dataset of 9.6 million (audio, question, answer) tuples, combining 13 datasets and using GPT-generated instructions to teach joint reasoning
Architecture
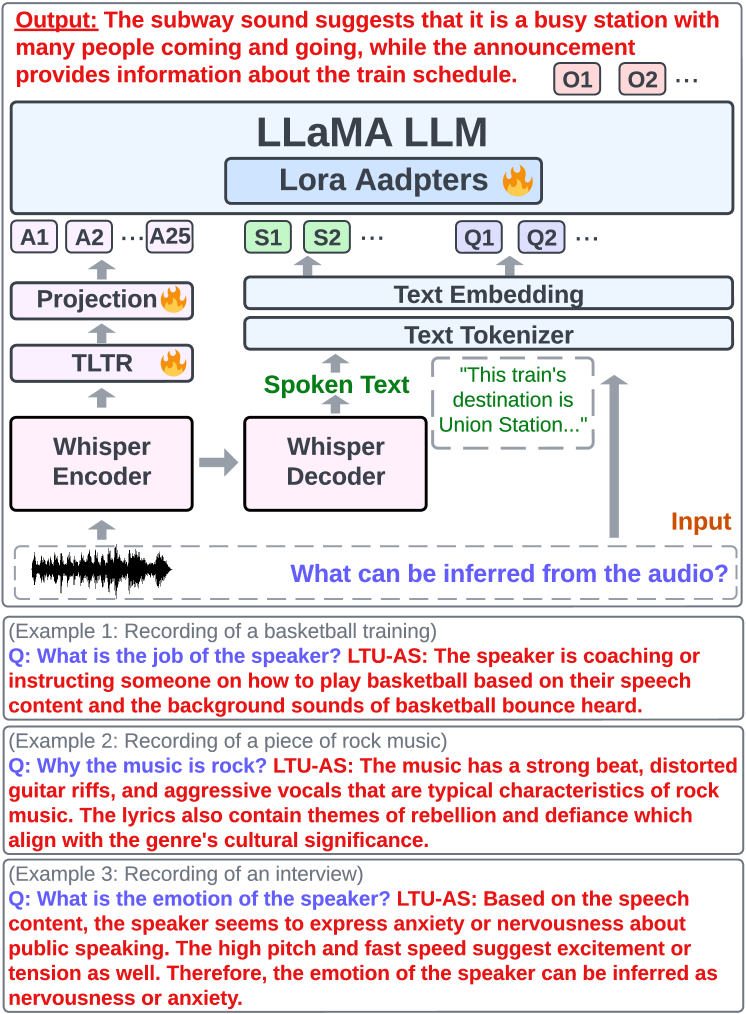
The LTU-AS architecture demonstrating the inputs (Audio, Question) and the dual pathway through Whisper (Decoder for text, TLTR for audio tokens) into LLaMA.
Evaluation Highlights
- Achieves an instruction following rate of over 95% on open-ended questions as evaluated by GPT-4
- Maintains strong ASR performance with 4.9% WER (Word Error Rate), retaining most of the frozen Whisper backbone's capability (3.5% WER)
- Outperforms CLAP on zero-shot music genre classification by nearly double the accuracy (qualitative claim in text, exact number not in snippet)
Breakthrough Assessment
8/10
Significant step in multimodal audio understanding. The 'dual-path' integration of text and audio features into an LLM is a robust architectural choice, supported by a massive new dataset (Open-ASQA).