📝 Paper Summary
Audio-driven Co-speech Gesture Generation
Conditional Diffusion Models
DiffGesture generates high-fidelity, audio-aligned co-speech gestures using a diffusion model conditioned on audio and initial poses, featuring a specialized stabilizer to ensure smooth temporal motion.
Core Problem
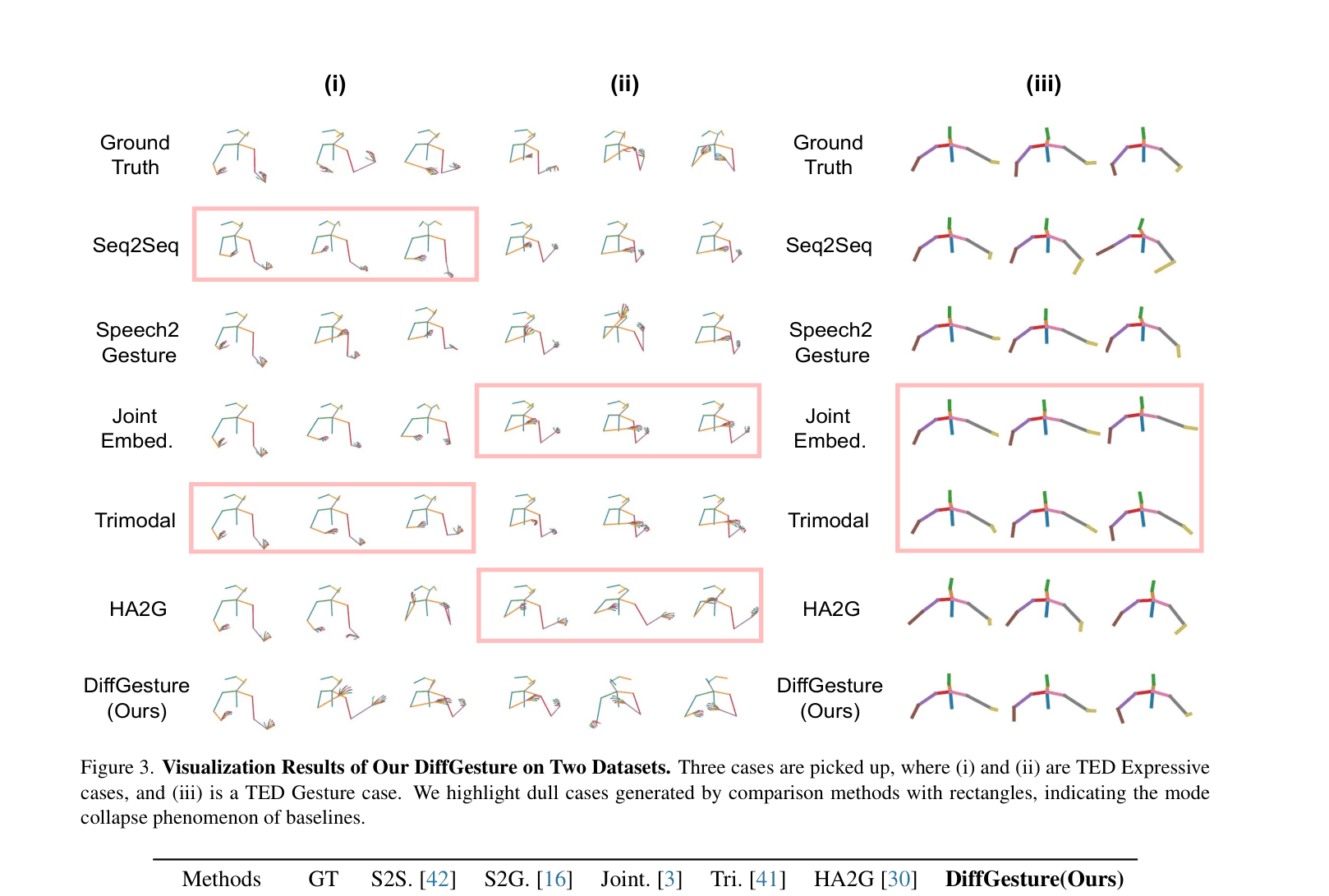
Existing GAN-based methods for co-speech gesture generation suffer from mode collapse and unstable training, failing to capture complex audio-gesture distributions.
Why it matters:
- Animating virtual avatars with realistic co-speech gestures is crucial for human-machine interaction and embodied AI
- Current GAN approaches often produce dull, repetitive, or unreasonable poses due to difficulty in learning the high-fidelity distribution
- Naive application of diffusion models to sequential data introduces temporal jitter (inconsistency) because standard denoising adds independent noise per frame
Concrete Example:
When generating gestures for a long speech clip, a standard diffusion model might produce diverse poses for each individual frame that, when played together, look jittery or incoherent because the noise sampling ignores temporal continuity. GANs often collapse to a 'mean pose' that looks safe but lacks expressive variation.
Key Novelty
Diffusion Co-Speech Gesture (DiffGesture)
- Models the gesture generation as a conditional diffusion process on entire skeleton sequences, treating gesture clips as the latent space
- Uses a Diffusion Audio-Gesture Transformer to attend to multi-modal context (audio, initial poses) across long temporal dependencies
- Introduces a Diffusion Gesture Stabilizer that anneals noise variance over time during sampling to eliminate temporal jitter without retraining
Architecture
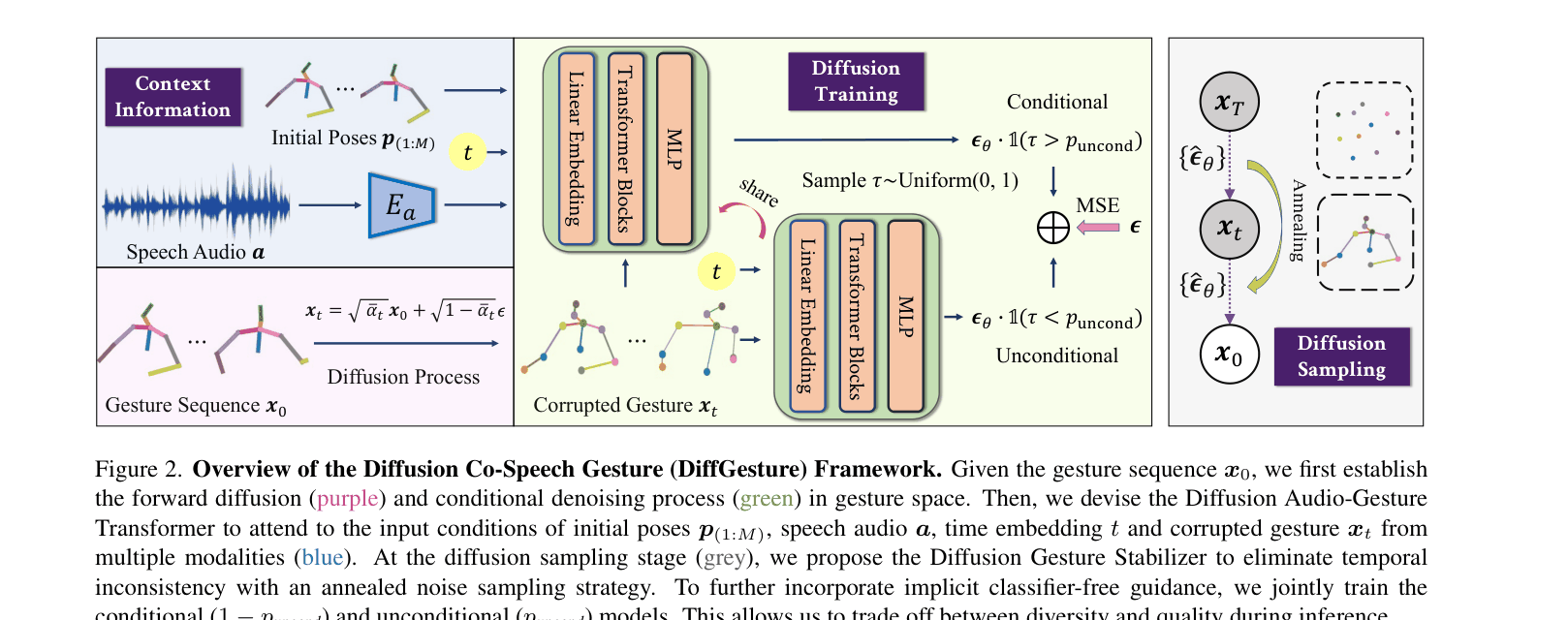
Overview of the DiffGesture framework including the forward diffusion process, the reverse conditional denoising transformer, and the stabilizer sampling.
Evaluation Highlights
- Achieves state-of-the-art Fréchet Gesture Distance (FGD) of 1.506 on TED Gesture, significantly outperforming the previous best (HA2G: 3.072)
- Improves FGD on TED Expressive to 2.600 compared to HA2G's 5.306, demonstrating better handling of complex finger movements
- Enhances diversity on TED Expressive (182.757 vs HA2G's 173.899) while maintaining high beat consistency (BC)
Breakthrough Assessment
8/10
First successful adaptation of diffusion models to the specific challenges of co-speech gesture generation, solving the critical temporal consistency issue inherent to frame-wise noise sampling.