📝 Paper Summary
3D Facial Animation
Audio-Driven Animation
Cross-Modal Generation
Media2Face uses a generalized neural parametric asset to create a large-scale pseudo-4D dataset, training a latent diffusion model that generates stylized facial animations and head poses from speech.
Core Problem
Existing speech-driven animation methods lack realism due to scarce high-quality 4D data and struggle to integrate flexible style/emotion control (e.g., from text or images) alongside natural head poses.
Why it matters:
- Current datasets like VOCASET are too small (0.5 hours) and lack emotional diversity, limiting the expressiveness of trained models
- Previous methods often ignore head poses or generate them independently, leading to unnatural decoupling from facial expressions
- Restricted conditioning (audio-only or fixed class labels) prevents nuanced, user-directed stylization needed for immersive virtual avatars
Concrete Example:
When driving a 3D character with sad speech, standard methods like FaceFormer generate accurate lip-sync but a rigid, staring face. Media2Face, conditioned on a 'sad' image prompt, generates the same lip-sync but adds a lowered head pose and sorrowful micro-expressions.
Key Novelty
The Media2Face Trilogy (Asset, Dataset, Model)
- Develops GNPFA (Generalized Neural Parametric Facial Asset), a VAE that maps diverse facial geometries to a unified latent space, decoupling expression from identity
- Creates M2F-D, a massive 60+ hour dataset, by using GNPFA to extract high-fidelity expression latents and poses from standard 2D video datasets
- Trains a latent diffusion model on this space that accepts loose multi-modal guidance (audio, text, images) via classifier-free guidance
Architecture
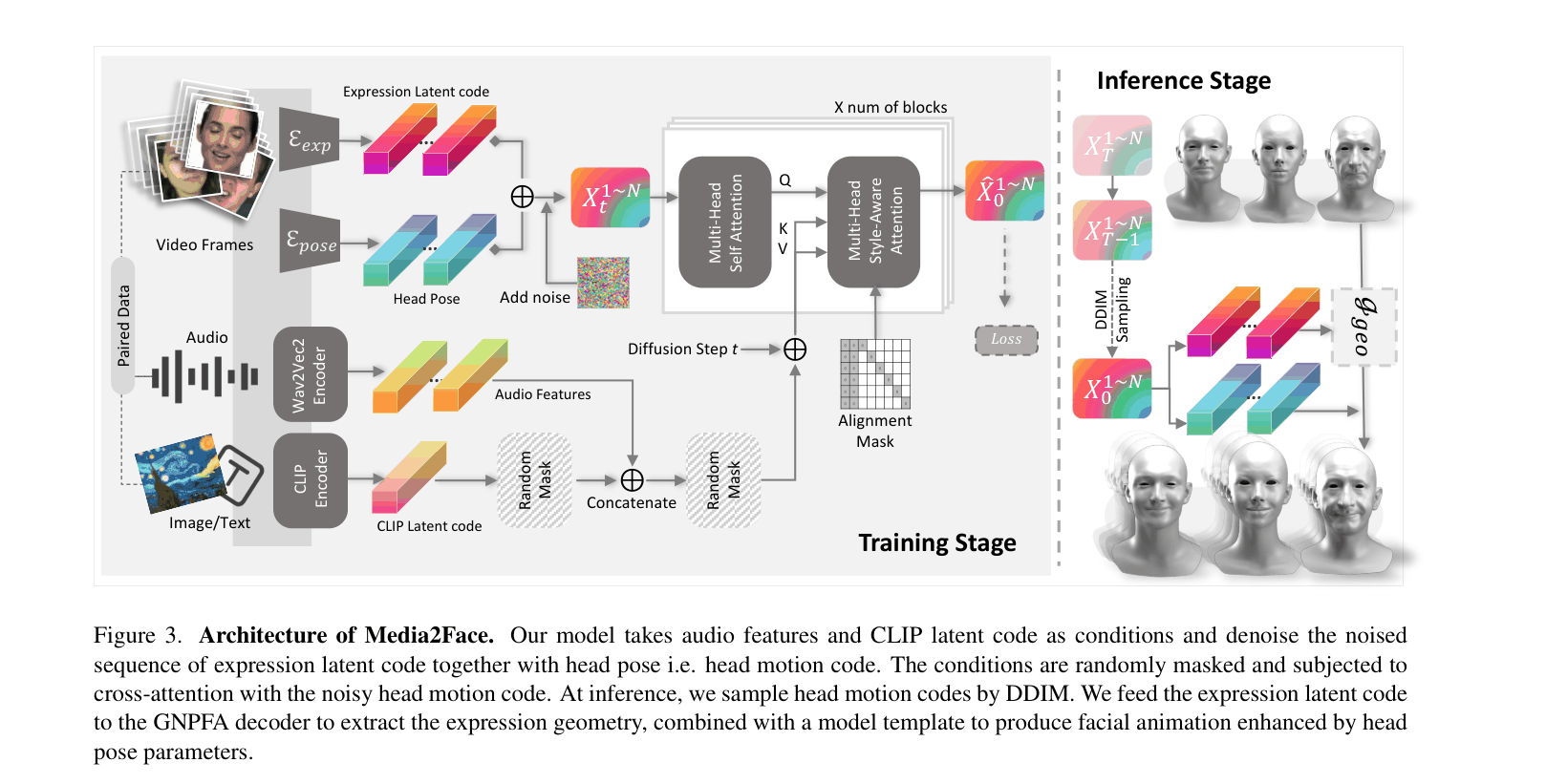
The Media2Face inference architecture showing the flow from multi-modal inputs to facial animation.
Evaluation Highlights
- Achieves 10.44mm Lip Vertex Error (LVE), outperforming state-of-the-art EmoTalk (14.61mm) and FaceFormer (18.19mm) by significant margins
- Reduces Face Dynamics Deviation (FDD) to 12.21, significantly better than the best baseline FaceDiffuser (22.38), indicating superior motion realism
- Attains 0.254 Beat Alignment (BA) score, surpassing SadTalker (0.219), demonstrating better synchronization between speech rhythm and generated head poses
Breakthrough Assessment
8/10
Significant contribution in data scaling (creating a 60hr dataset from 2D videos) and unifying expression/pose generation. High-quality results, though relies on existing architectures (Diffusion/VAE).
