📝 Paper Summary
Inference Acceleration
Speculative Decoding
Speculative Streaming accelerates LLM inference by integrating n-gram prediction directly into the target model via multi-stream attention, eliminating the need for separate draft models while maintaining generation quality.
Core Problem
Standard speculative decoding requires training, hosting, and aligning a separate auxiliary draft model for each downstream task, which increases system complexity and memory usage.
Why it matters:
- Managing separate draft models for every specific application becomes operationally expensive and complex as the number of tasks grows
- Loading two models (draft and target) into memory is inefficient for resource-constrained devices
- Existing single-model solutions like Medusa often lack dependencies between speculated tokens, limiting their effectiveness
Concrete Example:
In a SQL generation task, a standard approach would need to load a draft model (e.g., OPT-125m) alongside the target (OPT-1.3b). If the draft model isn't perfectly aligned, it generates poor candidates like 'SELECT * FROM table', forcing the target to reject them and waste compute. Speculative Streaming allows the target model itself to predict 'SELECT * FROM' in one pass using internal streams.
Key Novelty
Multi-Stream Attention for Self-Speculation
- Replaces the top layers of the target model with Multi-Stream Attention (MSA) layers that can predict an n-gram tree of future tokens in parallel
- Introduces 'speculative streams' that attend to the main stream and each other, allowing the model to 'plan' future tokens rather than just guessing blindly
- Uses a parallel tree pruning mechanism based on early-exit logits to discard unlikely token paths before they waste verification compute
Architecture
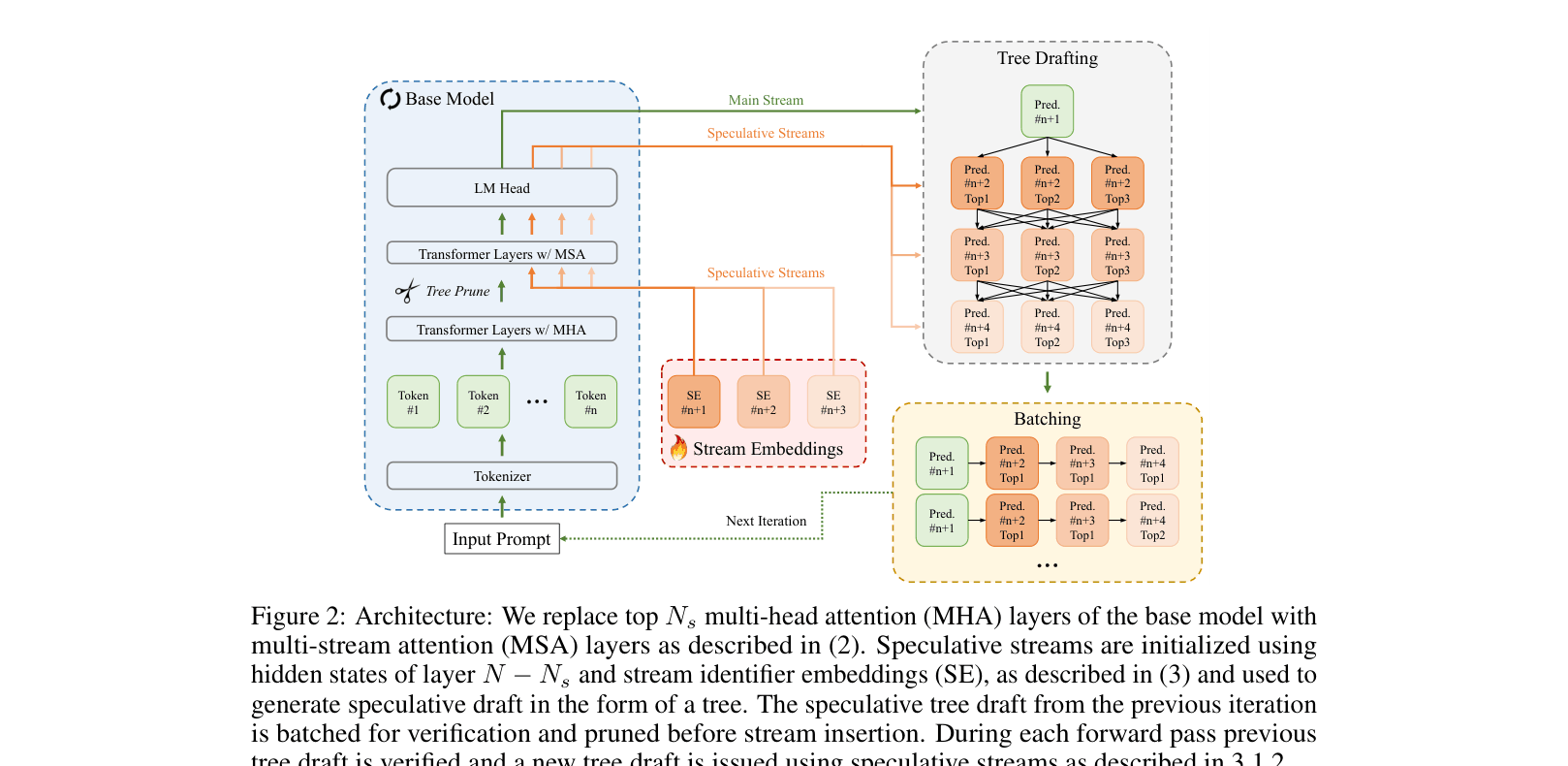
The Speculative Streaming architecture showing how Multi-Stream Attention (MSA) layers replace the top layers of the base model to perform parallel speculation and verification.
Evaluation Highlights
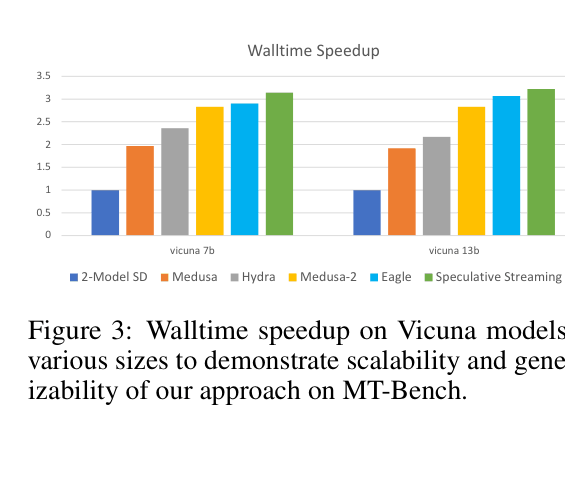
- Achieves 1.9X - 3X speedup across summarization, structured queries, and reasoning tasks compared to standard autoregressive decoding
- Uses ~10,000X fewer extra parameters than alternative architectures like Medusa (8.2E4 vs 5.9E8 parameters)
- Outperforms standard two-model speculative decoding in walltime speedup on diverse tasks while improving generation quality metrics (e.g., +0.5 EM on SqlContext)
Breakthrough Assessment
8/10
Significant for on-device LLMs. It eliminates the draft model requirement while outperforming existing single-model methods in speed and parameter efficiency. The massive reduction in extra parameters is a strong engineering win.