📝 Paper Summary
Multimodal Large Language Models (MLLMs)
Speech-to-Speech Interaction
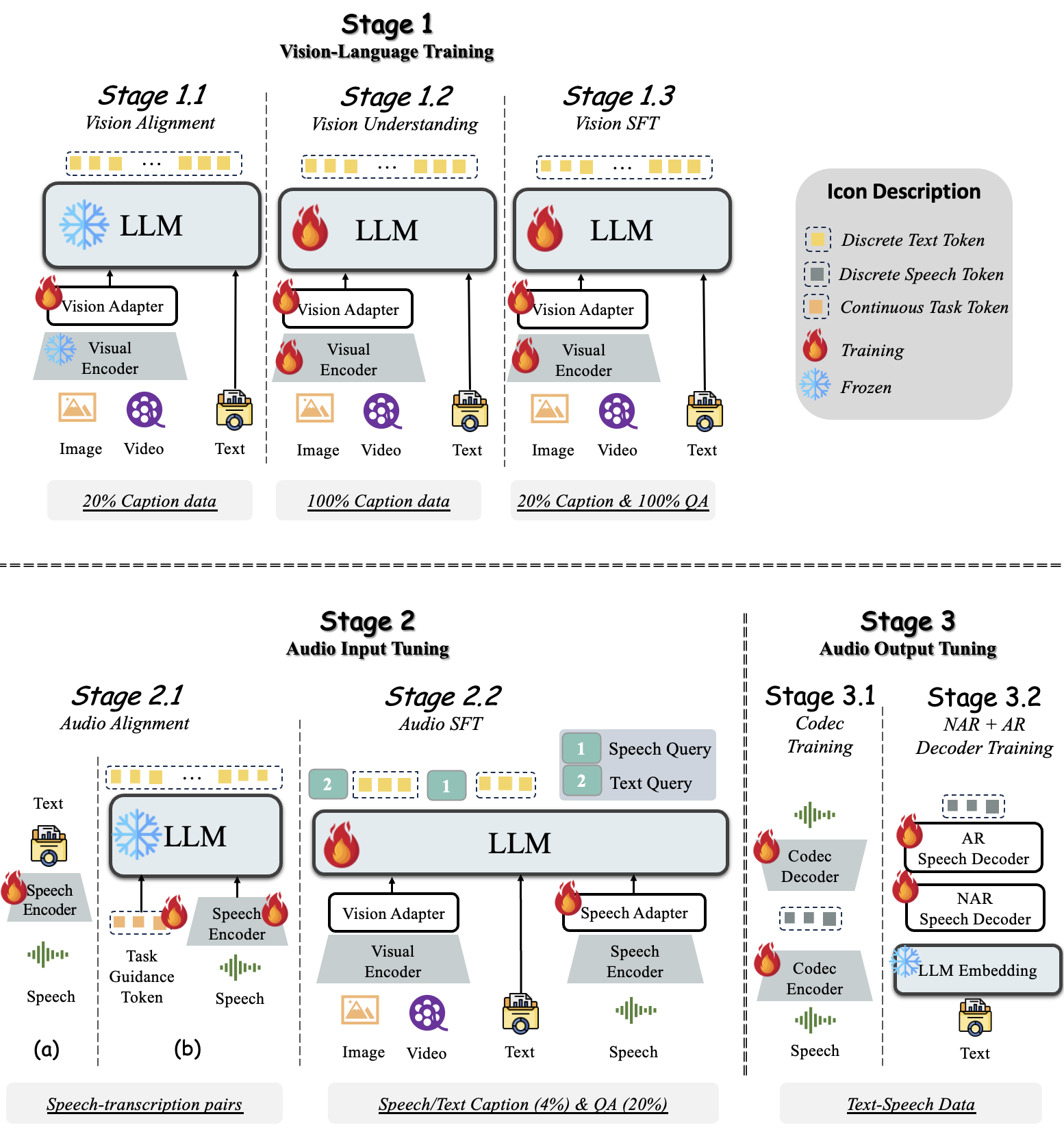
VITA-1.5 integrates vision, text, and speech into a single model via a three-stage training process, enabling real-time spoken dialogue about visual content without external speech recognition or text-to-speech modules.
Core Problem
Integrating speech into visual language models often causes modality conflicts (e.g., speech data degrading vision performance) and relies on slow external cascading modules for speech processing.
Why it matters:
- Current open-source models lag behind proprietary ones like GPT-4o in handling real-time, natural speech interactions alongside vision.
- Cascaded systems (ASR + LLM + TTS) suffer from high latency and lose paralinguistic features like emotion and tone.
- Simultaneous optimization of vision (spatial) and speech (temporal) modalities is difficult due to their fundamental differences.
Concrete Example:
A traditional system answering a question about a video must first transcribe audio (ASR), process text (LLM), and generate speech (TTS), causing noticeable delays. VITA-1.5 processes audio tokens directly to generate speech tokens, skipping these steps for faster response.
Key Novelty
Three-Stage Progressive Training Strategy
- Aligns vision and text first to establish strong visual understanding foundations before introducing audio.
- Incorporates audio input capability via an encoder trained with ASR (Automatic Speech Recognition) tasks, preventing interference with visual knowledge.
- Enables end-to-end speech output by training a native speech decoder, removing the need for external Text-to-Speech (TTS) systems.
Architecture
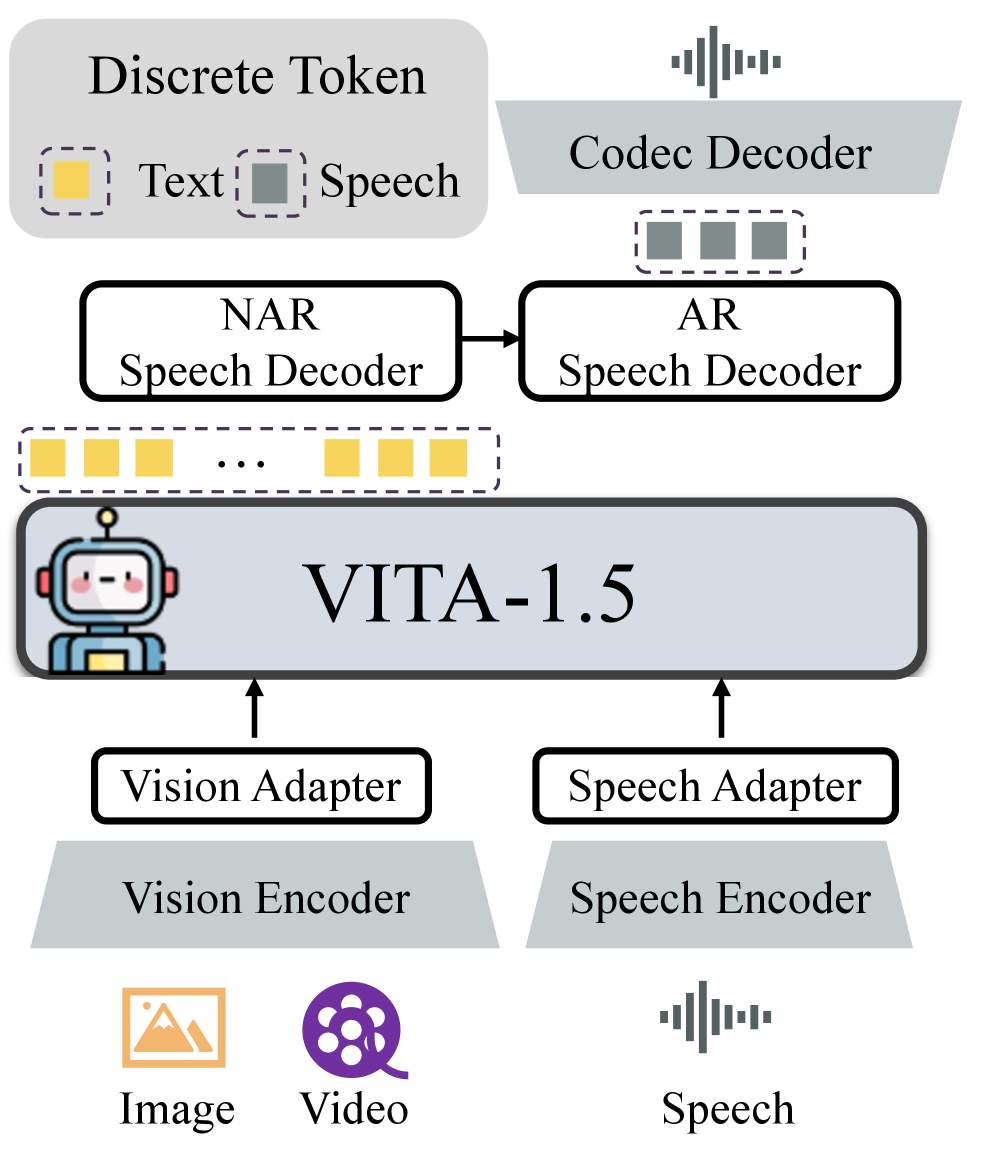
Overall architecture of VITA-1.5 showing the Multimodal Encoder-Adapter-LLM setup and the specialized Speech Decoder branch.
Evaluation Highlights
- Achieves comparable perception and reasoning capabilities to leading image/video-based MLLMs while adding speech functionality.
- Successfully eliminates the need for separate ASR and TTS modules, significantly accelerating multimodal end-to-end response speed.
- Demonstrates robust performance across image, video, and speech benchmarks, bridging the gap between open-source models and GPT-4o.
Breakthrough Assessment
8/10
Significant step for open-source MLLMs by achieving native end-to-end speech interaction with vision, a capability previously dominated by proprietary models like GPT-4o.