📝 Paper Summary
Sign Language Generation (SLG)
Masked Diffusion Models
Cross-modal Pretraining
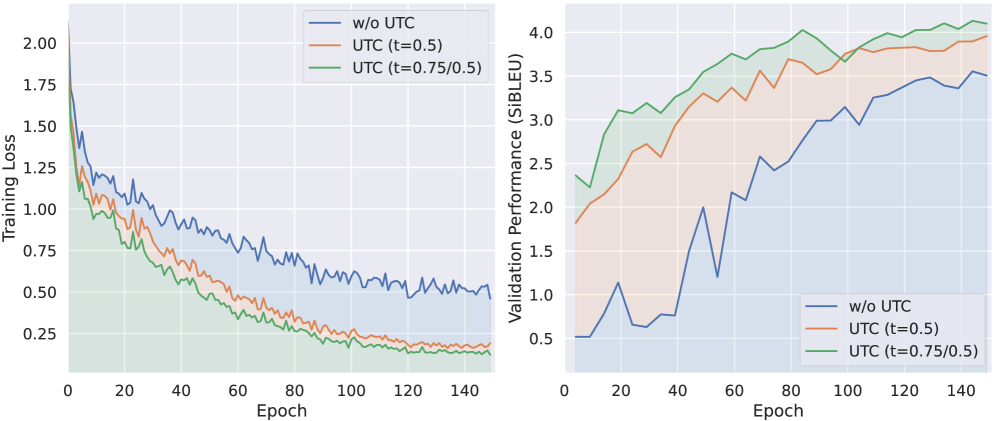
MaDiS adapts masked diffusion language models for sign language generation by introducing tri-level pretraining and a temporal-checkpoint unmasking strategy to enable bidirectional context modeling and faster inference.
Core Problem
Existing autoregressive language models (ARLMs) for sign language generation are limited by unidirectional (left-to-right) context modeling and slow token-by-token serial inference.
Why it matters:
- Left-to-right generation fails to capture future context crucial for sign language grammar and motion planning
- Serial decoding creates an inference bottleneck, hindering real-time applications for Deaf and Hard-of-Hearing communities
- Current methods lack grounded pretraining, missing the 3D physical nature of sign motions
Concrete Example:
Generating a 100-token sign sequence with an ARLM requires 100 sequential steps. MaDiS can generate the same sequence in ~25 steps by sampling multiple tokens in parallel, while correcting early errors using bidirectional context.
Key Novelty
Masked Diffusion Language Model (MDLM) for Sign Language
- Replaces autoregressive decoding with a bidirectional masked diffusion process, allowing the model to predict any token based on any context (past or future)
- Introduces 'unmasking with temporal checkpoints' (UTC) to prune the vast search space of diffusion steps, enforcing coarse-to-fine generation
- Tri-level pretraining forces the model to learn signs not just as tokens, but also as latent codebook features and physical 3D motions simultaneously
Architecture
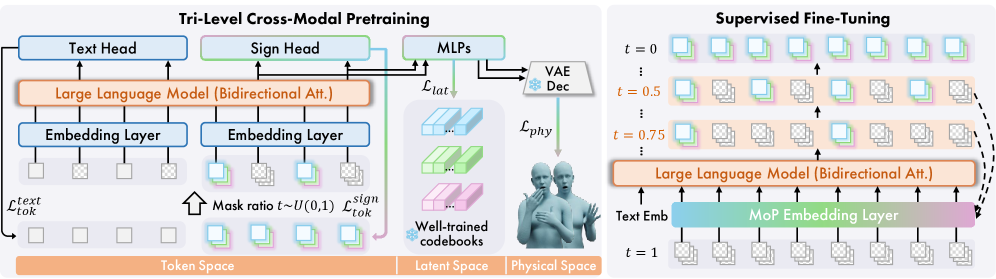
Overview of MaDiS pipeline including Tri-Level Pretraining and Fine-tuning stages.
Evaluation Highlights
- Achieves state-of-the-art DTW-JPE error of 6.22 on Phoenix-2014T, outperforming the previous best (SOKE) by 0.54 points
- Reduces inference latency by ~30% compared to autoregressive baselines (e.g., 6.36s vs 9.20s on CSL-Daily)
- Improves text-to-sign retrieval (R@1) by over 3.0 points on CSL-Daily using the new SiCLIP metric
Breakthrough Assessment
8/10
First successful application of MDLMs to sign language generation. The method significantly improves both quality and speed, addressing the core bottleneck of autoregressive approaches.