📝 Paper Summary
Multilingual Language Models
Low-Resource NLP
The paper introduces Linguistic Entity Masking (LEM), a pre-training strategy that selectively masks single tokens from Named Entities, Nouns, and Verbs to improve cross-lingual representations for low-resource languages.
Core Problem
Standard Masked Language Modeling (MLM) and Translation Language Modeling (TLM) mask tokens randomly, ignoring linguistic importance, which leads to suboptimal cross-lingual representations for low-resource languages (LRLs).
Why it matters:
- Current multilingual models (like XLM-R) often underperform on LRLs due to a lack of explicit cross-lingual alignment objectives beyond random masking.
- Morphologically rich LRLs suffer from over-segmentation into many sub-words; masking long spans of these sub-words destroys context needed for learning.
- Bitext mining and parallel data curation are critical for training Neural Machine Translation systems for LRLs but rely heavily on high-quality sentence embeddings.
Concrete Example:
In the sentence 'Jack walks towards the road', 'Jack' (NE) and 'walks' (Verb) carry the most semantic weight. Standard MLM might randomly mask 'towards', which is less informative. LEM ensures 'Jack' or 'walks' is masked to force the model to focus on semantically dense tokens.
Key Novelty
Linguistic Entity Masking (LEM)
- Targeted Masking: Instead of random selection, LEM specifically targets Named Entities (NEs), Nouns, and Verbs for masking because they hold higher prominence and attention weights in sentences.
- Single Token Constraint: Unlike span masking, LEM masks only a *single* token from a multi-token linguistic entity. This preserves more context, which is crucial for morphologically rich languages where words split into many sub-words.
Architecture
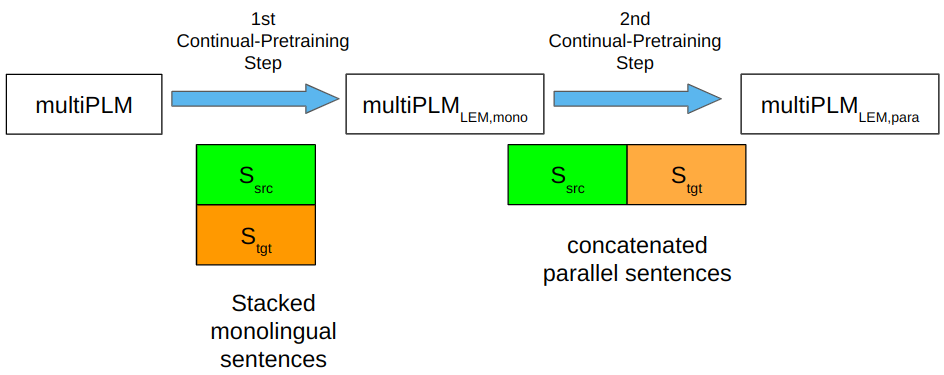
The two-stage continual pre-training process for XLM-R using LEM.
Evaluation Highlights
- XLM-R continually pre-trained with LEM outperforms the MLM+TLM baseline on bitext mining recall across English-Sinhala, English-Tamil, and Sinhala-Tamil pairs.
- Parallel data curated using LEM-based embeddings improves Neural Machine Translation (NMT) performance (measured by ChrF) compared to baselines.
- LEM improves code-mixed sentiment analysis F1 scores for English-Sinhala compared to standard XLM-R baselines.
Breakthrough Assessment
5/10
A solid incremental improvement for low-resource languages. It refines existing masking strategies with linguistic intuition but doesn't propose a radical new architecture. Evaluation is limited to three language pairs.