📝 Paper Summary
Large Audio Language Models (LALMs)
Reinforcement Learning (RL)
Multimodal Reasoning
Audio-Thinker improves multimodal reasoning by using reinforcement learning with adaptive rewards to teach models when to engage in deep thinking and model-based supervision to ensure reasoning quality.
Core Problem
Current Large Audio Language Models (LALMs) lack the ability to adaptively decide when to reason based on difficulty, and their explicit reasoning processes (Chain-of-Thought) often lack coherence or do not improve accuracy.
Why it matters:
- Explicit reasoning in current audio models (like R1-AQA) has not yielded substantial benefits for Question Answering compared to direct answering
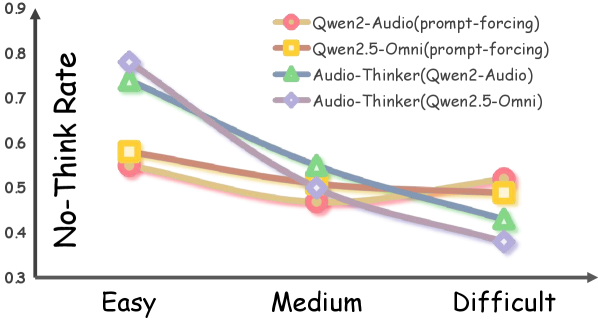
- Prompting alone fails to make models 'difficulty-aware'; they do not naturally adjust thinking depth based on problem complexity (Observation 2)
- Models can learn to produce correct answers with flawed or incoherent reasoning logic if only the final answer is supervised
Concrete Example:
A model might correctly answer '1' but generate a reasoning chain that concludes 'the final answer is 1' after outputting unrelated or erroneous logic (e.g., <think>...answer is 1</think><answer>2</answer>), showing misalignment between thought and output.
Key Novelty
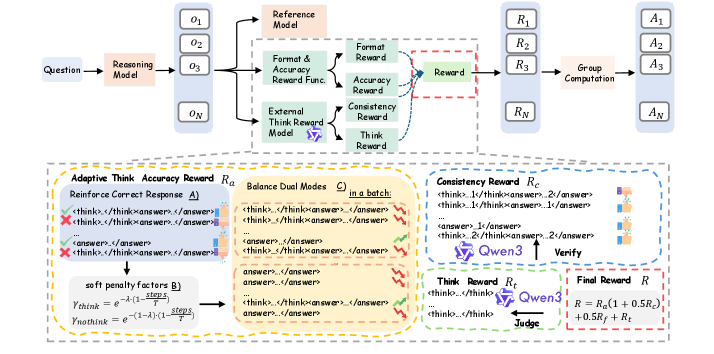
Adaptive & Quality-Aware Reinforcement Learning Framework (Audio-Thinker)
- Introduces an 'Adaptive Think Accuracy Reward' that incentivizes the model to skip reasoning for easy questions (efficiency) and engage in it for hard ones, correcting the static behavior of prior models
- Uses an external 'Expert LLM' (Qwen3-8B-Base) to act as a reward model, scoring the *quality* and *consistency* of the reasoning process itself, not just the final answer accuracy
Architecture
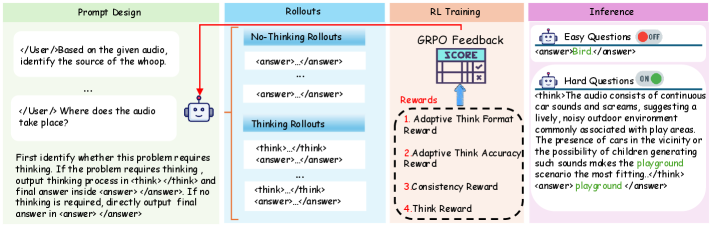
Overview of the Audio-Thinker framework, showing the prompt design and the RL training loop.
Breakthrough Assessment
7/10
Addresses a critical gap in multimodal reasoning (adaptability and process supervision) with a well-motivated RL framework. Score limited only by the lack of visible experimental validation in the provided text.