📝 Paper Summary
Reinforcement Learning from Human Feedback (RLHF)
Reward Modeling
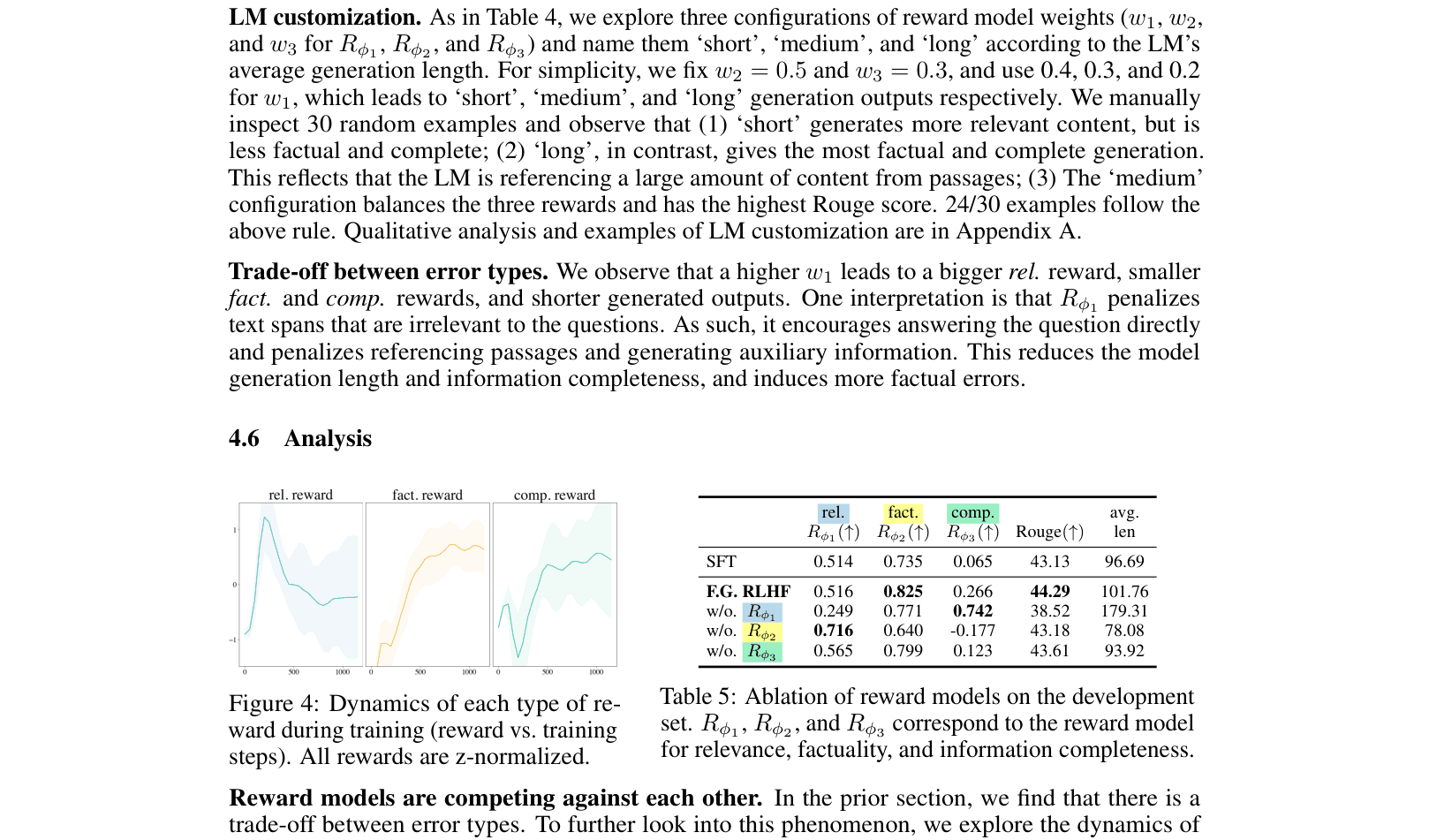
Fine-Grained RLHF improves language model training by using multiple dense reward models targeting specific error types (factuality, relevance, completeness) at different granularities (sentence, sub-sentence), rather than a single holistic preference score.
Core Problem
Standard RLHF uses a single scalar reward for an entire text sequence, which provides sparse training signals and fails to indicate which specific parts of a long output are problematic (e.g., false, toxic, or irrelevant).
Why it matters:
- Holistic feedback conveys limited information for long-form text generation, making RLHF unreliable in complex domains like long-form QA
- Annotators struggle to reliably compare overall quality when outputs contain a mixture of diverse errors (e.g., one output is factual but irrelevant, another is relevant but false)
Concrete Example:
In long-form QA, a model might generate a paragraph where the first sentence is factual but the second is irrelevant. Standard RLHF gives one score for the whole paragraph, obscuring the specific error. Fine-Grained RLHF assigns a positive factual reward to sentence 1 and a negative relevance reward to sentence 2.
Key Novelty
Fine-Grained RLHF Framework
- Introduces dense rewards: providing feedback after every segment (e.g., sentence or sub-sentence) rather than just at the end of the full sequence
- Utilizes multiple reward models: training separate models for distinct error categories (e.g., irrelevance, incorrect facts, incompleteness) and combining them during RL optimization
- Enables customization: allows adjusting weights of different reward models during training to control trade-offs between behaviors (e.g., prioritizing factuality over length)
Architecture
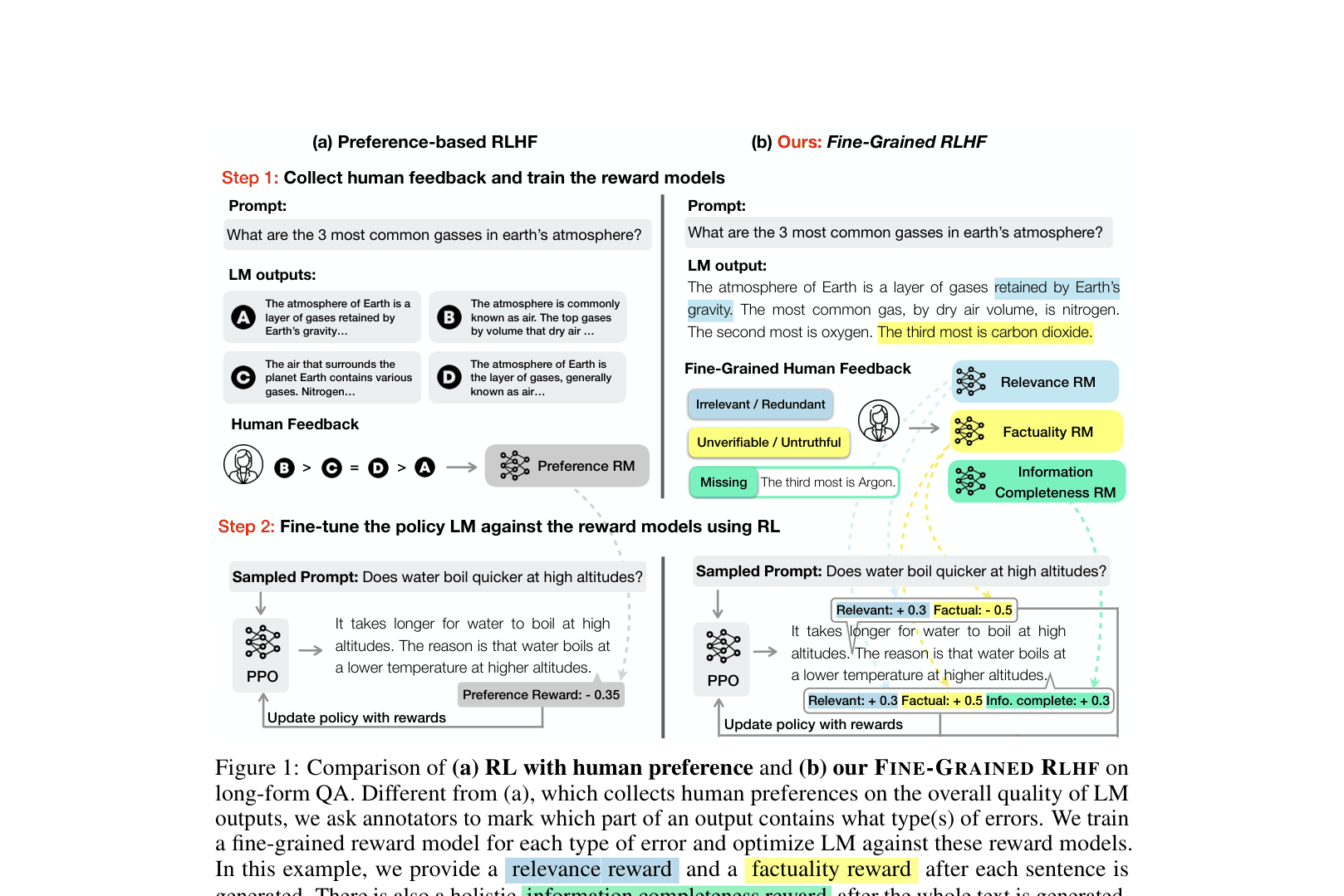
Contrast between Preference-based RLHF (Holistic) and Fine-Grained RLHF architecture.
Evaluation Highlights
- Fine-Grained RLHF reduces toxicity to 0.081 on RealToxicityPrompts, outperforming holistic RLHF (0.130) and controlled generation baselines (GeDi: 0.154)
- In Long-Form QA, Fine-Grained RLHF reduces factual error rate (sub-sentences with errors) vs. Preference RLHF, with human evaluation showing improved factuality (0.816 vs 0.781 reward score)
- Human annotators rated Fine-Grained RLHF better than Preference-based RLHF in 30.5% of cases (vs 24.5% worse) despite Preference RLHF being optimized directly for preference
Breakthrough Assessment
8/10
Significant methodological advancement in RLHF by moving from sparse/holistic to dense/fine-grained rewards. Demonstrates clear gains in sample efficiency and control over specific model behaviors.