📝 Paper Summary
Robotic Manipulation
Real-world Reinforcement Learning
Vision-Language-Action Models
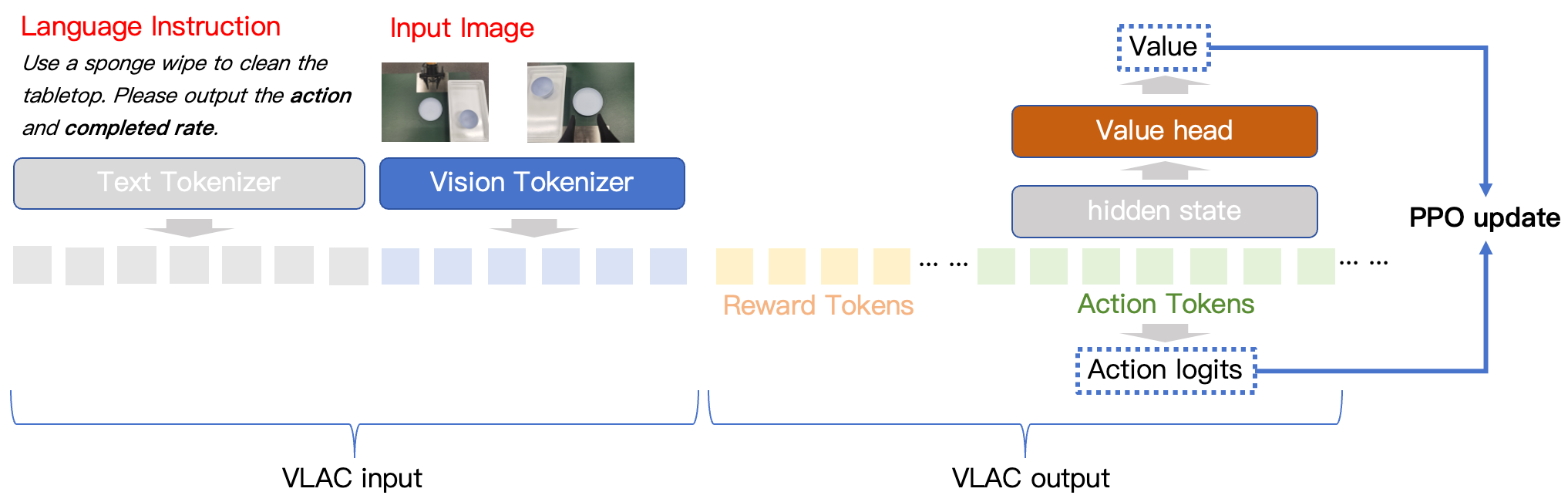
VLAC unifies a robotic policy (actor) and a visual progress estimator (critic) into a single multimodal model to provide dense, generalizable rewards for efficient real-world reinforcement learning.
Core Problem
Real-world robotic RL suffers from sparse rewards and inefficient exploration because standard VLAs lack dense feedback mechanisms and designing task-specific rewards is costly and non-generalizable.
Why it matters:
- Collecting human expert trajectories for every new task is expensive and time-consuming
- Existing 'universal' reward models often fail to generalize across novel objects or tasks, making intermediate feedback unreliable
- Current methods rely on handcrafted, task-specific reward shaping that cannot scale to general-purpose robots
Concrete Example:
In a task like 'picking up a bowl,' a standard VLA might fail repeatedly without knowing *why* or *how close* it was, receiving only a binary 'failure' signal at the end. VLAC compares intermediate frames to the goal description to output a score (e.g., '+0.1 progress'), guiding the robot even if the final grasp fails.
Key Novelty
Vision-Language-Action-Critic (VLAC)
- Unifies the 'Actor' (action generator) and 'Critic' (progress estimator) in one autoregressive model using different prompts, eliminating separate reward models.
- Trains the Critic on large-scale human videos by treating temporal ordering as a proxy for task progress, enabling zero-shot reward generation for unseen tasks.
- Implements a 'progress delta' mechanism where the model compares paired observations to output a signed value indicating advancement or regression.
Architecture
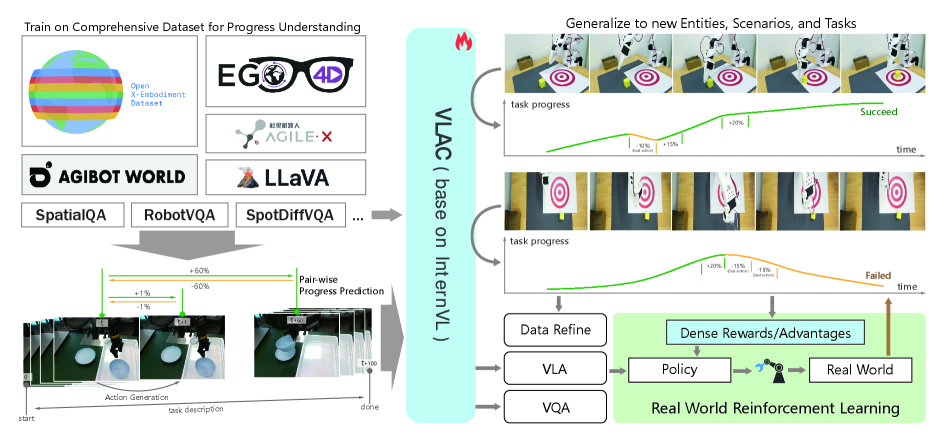
The unified VLAC architecture showing joint training on action robotics data and non-action human data.
Evaluation Highlights
- Improves success rates on four real-world manipulation tasks from ~30% (zero-shot) to ~90% within 200 interaction episodes.
- Human-in-the-loop interventions (demonstration replay, guided explore) improve sample efficiency by ~50% and achieve up to 100% success rates.
- Generalizes to unseen tasks by leveraging over 4000 hours of heterogeneous human and robot training data.
Breakthrough Assessment
8/10
Strong real-world results (30% -> 90%) and a clever architectural unification of VLA and Critic. The reliance on human-in-the-loop for peak performance is a slight caveat but practical for robotics.