📝 Paper Summary
Unsupervised Environment Design (UED)
Model-Based Reinforcement Learning
Robustness
WAKER trains robust world models in reward-free settings by actively sampling environments where the model's latent dynamics ensemble exhibits the highest disagreement.
Core Problem
Training generalist agents requires robustness across diverse environments, but existing curriculum learning methods (UED) depend on task-specific rewards, which are unavailable during reward-free pre-training.
Why it matters:
- Agents must adaptable to new tasks and physical dynamics without retraining from scratch, but standard Domain Randomization is inefficient for hard-to-learn variations.
- Current Unsupervised Environment Design (UED) methods cannot operate in the reward-free exploration phase, limiting the development of truly generalist autonomous agents.
Concrete Example:
A robot trained via standard randomization might spend equal time on high-friction and low-friction surfaces. However, low-friction 'ice' physics are harder to model. WAKER detects the higher prediction error on 'ice' and automatically prioritizes sampling that environment, whereas standard methods would ignore the model's uncertainty.
Key Novelty
WAKER (Weighted Acquisition of Knowledge across Environments for Robustness)
- Connects the robust optimization objective of 'minimax regret' to minimizing the maximum world model error across environment instances.
- Biases environment sampling towards parameter settings where an ensemble of latent dynamics models has the highest disagreement (proxy for error), without needing external rewards.
Architecture
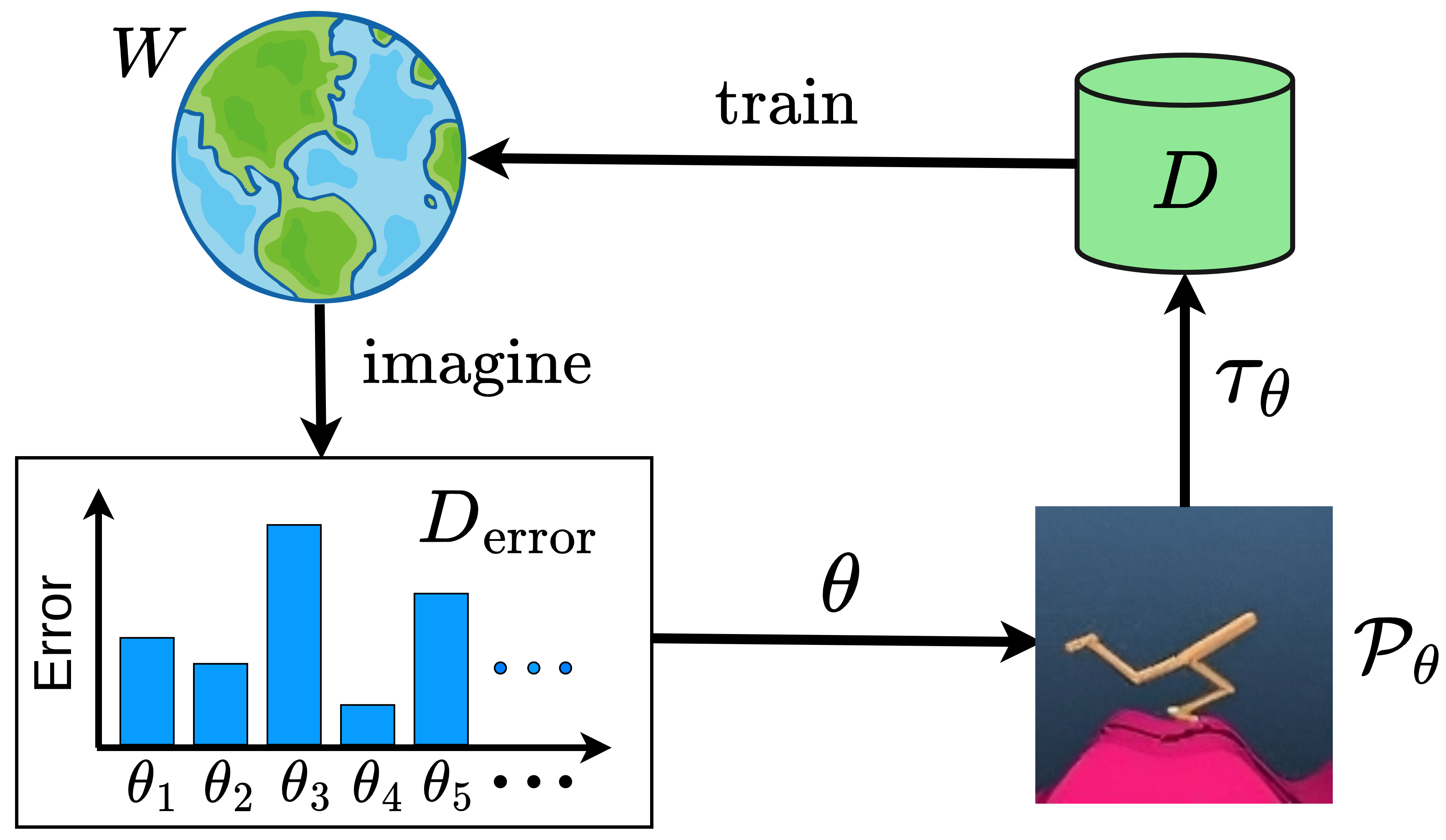
The WAKER training loop and environment selection process.
Evaluation Highlights
- Outperforms Domain Randomization and intrinsically-motivated baselines on distorted continuous control tasks.
- Demonstrates improved generalization to out-of-distribution (OOD) environments compared to random sampling.
- Successfully trains a single generalist policy that is robust across variations in environmental parameters (e.g., physics constants).
Breakthrough Assessment
7/10
Novel extension of Unsupervised Environment Design to the reward-free setting by theoretically linking minimax regret to model error. Addresses a significant gap in training generalist agents.