📝 Paper Summary
Offline Reinforcement Learning
Model-Based Reinforcement Learning (MBRL)
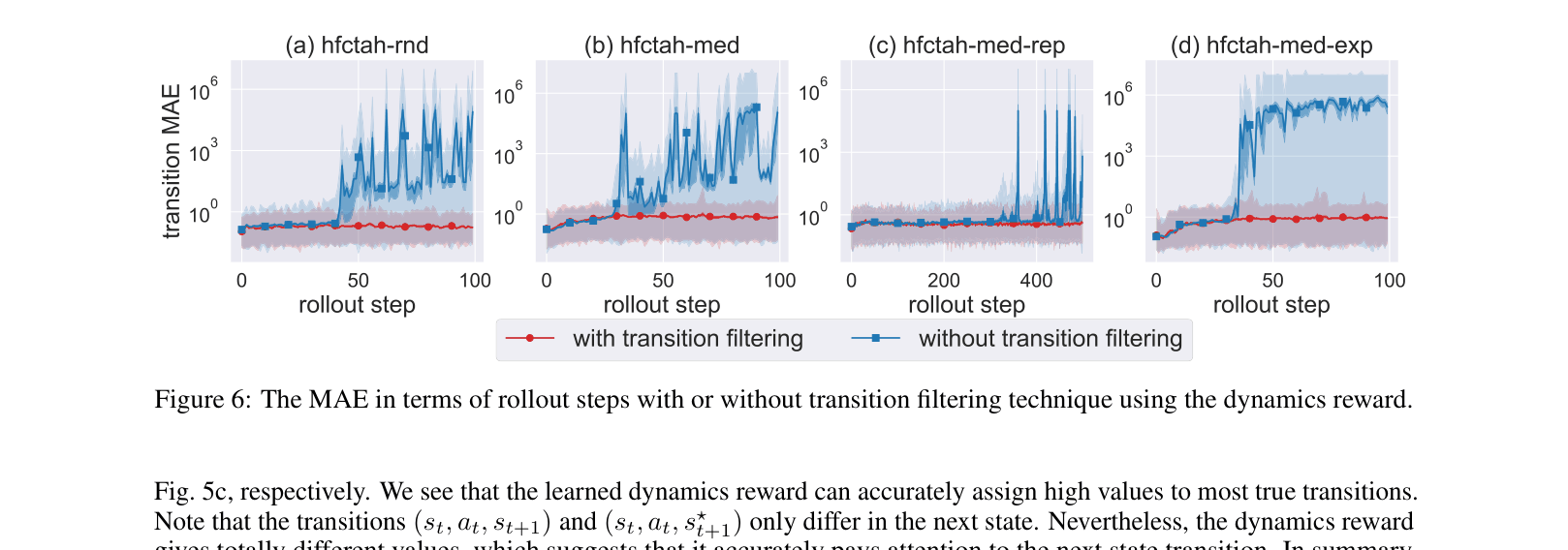
MOREC improves offline model-based RL by learning a reward function that identifies high-fidelity transitions, using it to filter out erroneous model rollouts during policy learning.
Core Problem
Learned dynamics models in offline RL struggle to generalize to unseen transitions (out-of-distribution errors) because they are trained via supervised learning on limited historical data.
Why it matters:
- Model errors in out-of-distribution regions are often exploited by policy optimization, leading to poor real-world performance
- Existing conservative methods limit policy exploration or pessimistically penalize the model, which restricts the potential performance gains from model-based approaches
- Current methods fail to distinguish between accurate and inaccurate model predictions when generating long-horizon rollouts
Concrete Example:
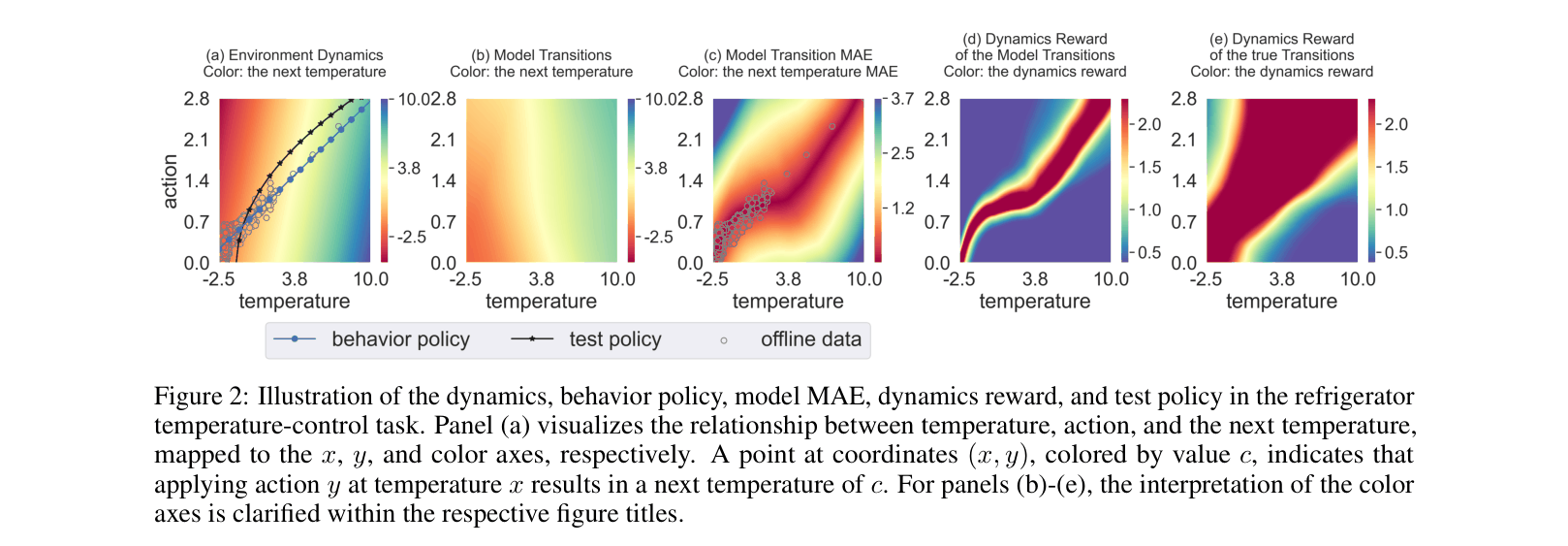
In a refrigerator temperature control task, a dynamics model trained on a specific behavior policy accurately predicts temperatures for that policy but fails when a new test policy visits unseen states. Without MOREC, the model generates erroneous temperature predictions that diverge from reality, causing the policy to fail.
Key Novelty
Model-based Offline Reinforcement learning with Reward Consistency (MOREC)
- Conceptualizes the environment dynamics as an agent maximizing a hidden 'dynamics reward' (consistency signal), which can be recovered via Inverse Reinforcement Learning (IRL)
- Uses this learned dynamics reward to filter transitions during model rollouts: instead of accepting any predicted next state, the system samples multiple candidates and selects the one with the highest dynamics reward
- Integrates seamlessly into existing model-based algorithms (like MOPO or MOBILE) by simply replacing the standard rollout mechanism with this reward-consistent filtering
Architecture
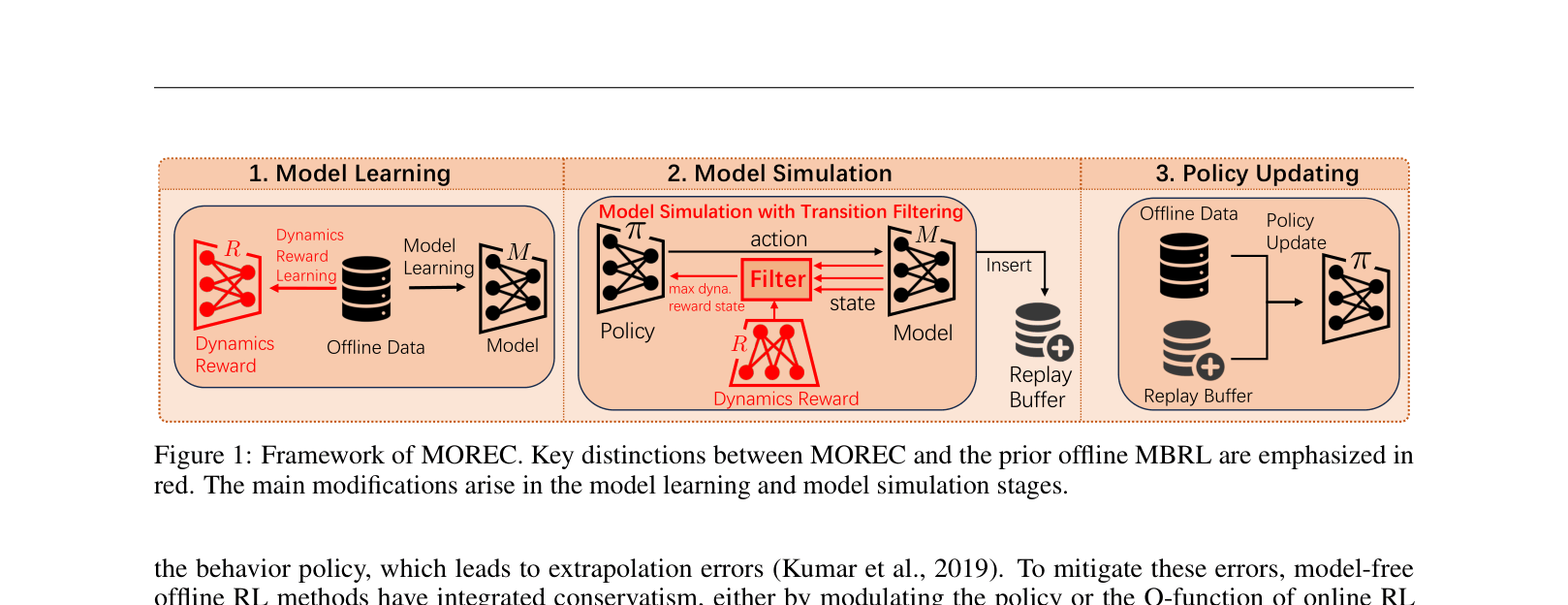
The MOREC framework pipeline compared to standard offline MBRL.
Evaluation Highlights
- Outperforms prior SOTA methods on 18 out of 21 tasks across D4RL and NeoRL benchmarks
- +25.9% average performance improvement over previous SOTA (MOBILE) on the challenging NeoRL benchmark
- First method to solve 3 tasks in the NeoRL benchmark (normalized score > 95), whereas previous methods solved 0
Breakthrough Assessment
8/10
Significant performance jumps on difficult benchmarks (NeoRL) and a novel conceptual framing of dynamics consistency as an IRL problem make this a strong contribution.