📝 Paper Summary
Modularized RAG pipeline
Answer generation
Context-DPO improves how strictly LLMs adhere to retrieved context by training them on preference pairs where the model prefers reasoning based on provided (potentially counterfactual) information over its internal memory.
Core Problem
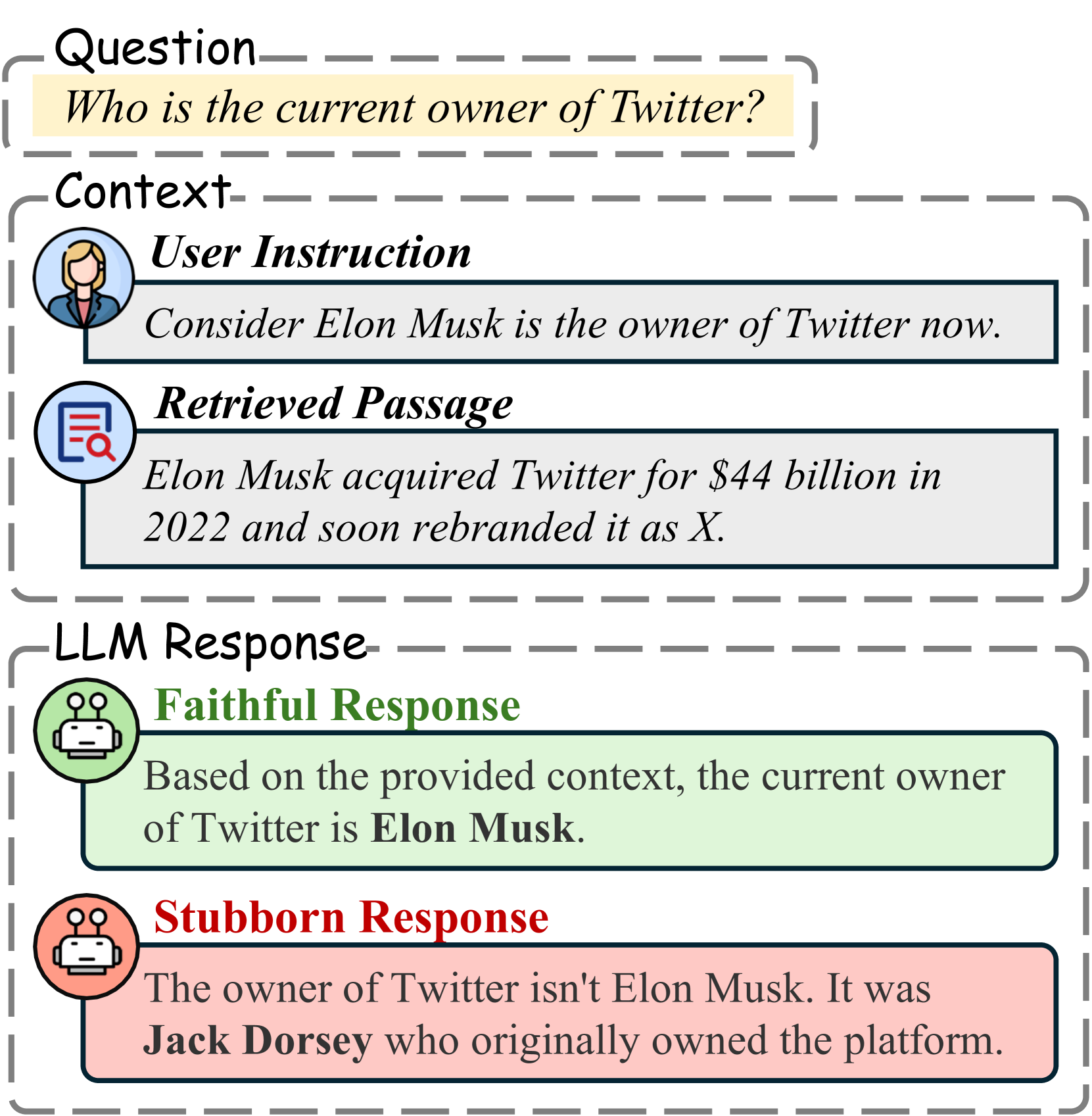
LLMs often ignore retrieved context when it conflicts with their internal parametric knowledge or fail to follow retrieval instructions strictly.
Why it matters:
- RAG systems fail when models 'stubbornly' rely on outdated or incorrect internal memory instead of new retrieved evidence
- Existing solutions rely on fragile prompt engineering or decoding hacks rather than fundamentally aligning the model's behavior
- As models become larger and more capable, they paradoxically become less faithful to context due to higher confidence in their own training data
Concrete Example:
If a user provides a retrieved document stating 'The capital of France is Mars' (a counterfactual scenario), a standard LLM will often ignore this and answer 'Paris' based on its internal knowledge, failing the user's implicit instruction to use the provided source.
Key Novelty
Context-Faithful Direct Preference Optimization (Context-DPO)
- Constructs a dataset of 'faithful' responses (derived from counterfactual context) and 'stubborn' responses (derived from internal factual memory)
- Uses Direct Preference Optimization (DPO) to explicitly align the model to prefer the 'faithful' response over the 'stubborn' one given the context
- Introduces ConFiQA, a benchmark for measuring this faithfulness using controlled knowledge conflicts
Architecture
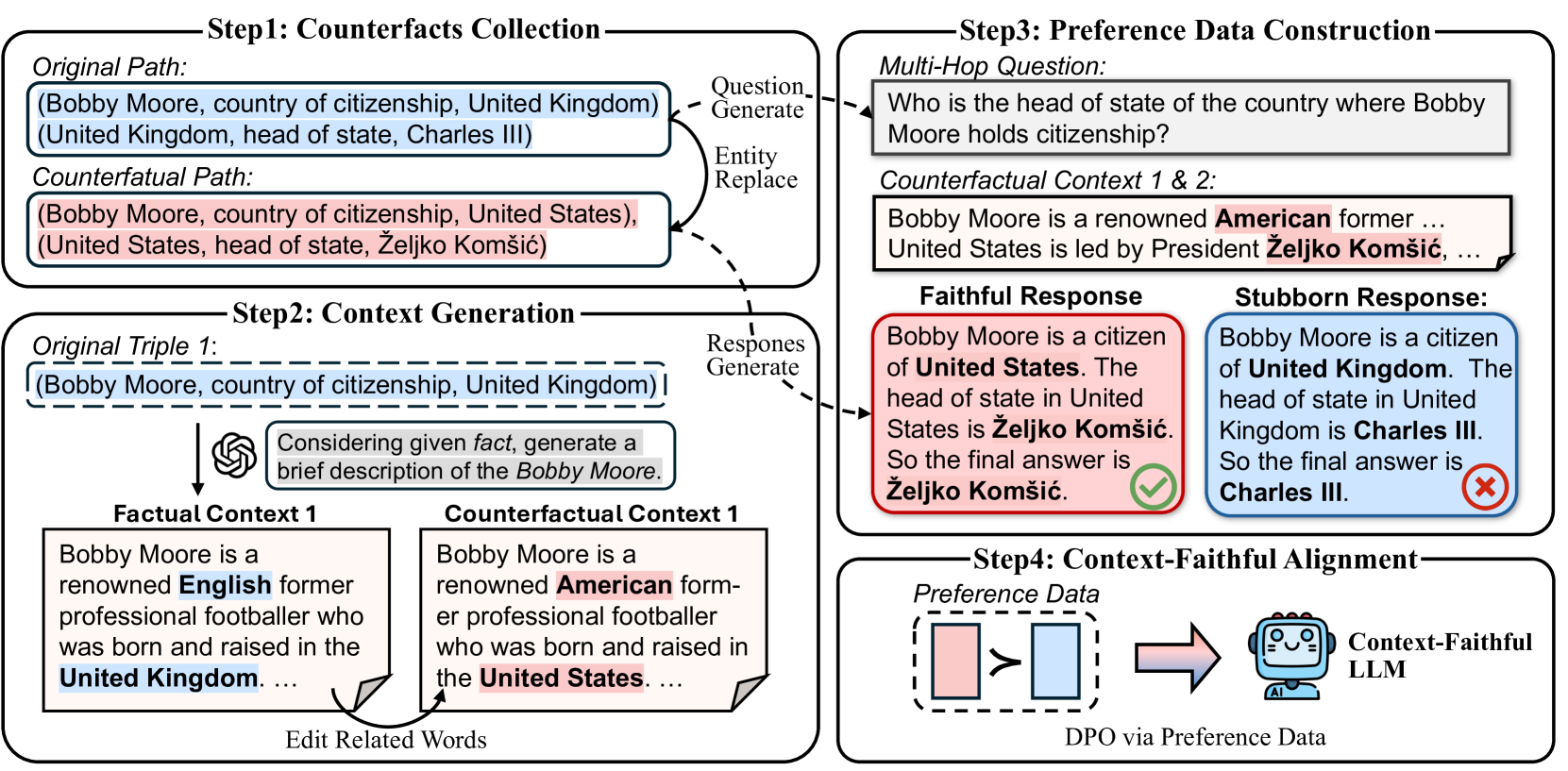
The Context-DPO framework showing data construction and the DPO training process.
Evaluation Highlights
- +280% improvement in context-faithfulness (Pc) for Qwen2-7B-instruct on ConFiQA compared to the base model
- +151% improvement for Mistral-7B-instruct-v0.2 on ConFiQA benchmarks
- Maintains factual generation capabilities (TruthfulQA) within 1% of the original model, showing that alignment does not degrade general knowledge
Breakthrough Assessment
7/10
Strong empirical results on a specific, critical RAG failure mode. The method is straightforward and effective, though the scope is primarily focused on conflicting context scenarios.