📝 Paper Summary
Text-to-Video Generation
Controllable Video Generation
Diffusion Models
Control-A-Video adapts a pre-trained image diffusion model for controllable video generation by introducing motion-adaptive noise initialization and optimizing the model with reward feedback on video quality and temporal consistency.
Core Problem
Existing text-to-video (T2V) methods struggle to produce high-quality, motion-consistent videos, often suffering from flickering artifacts and object inconsistency when generating sequences.
Why it matters:
- Current T2V models often lack fine-grained control over structure and motion, limiting their utility for professional content creation
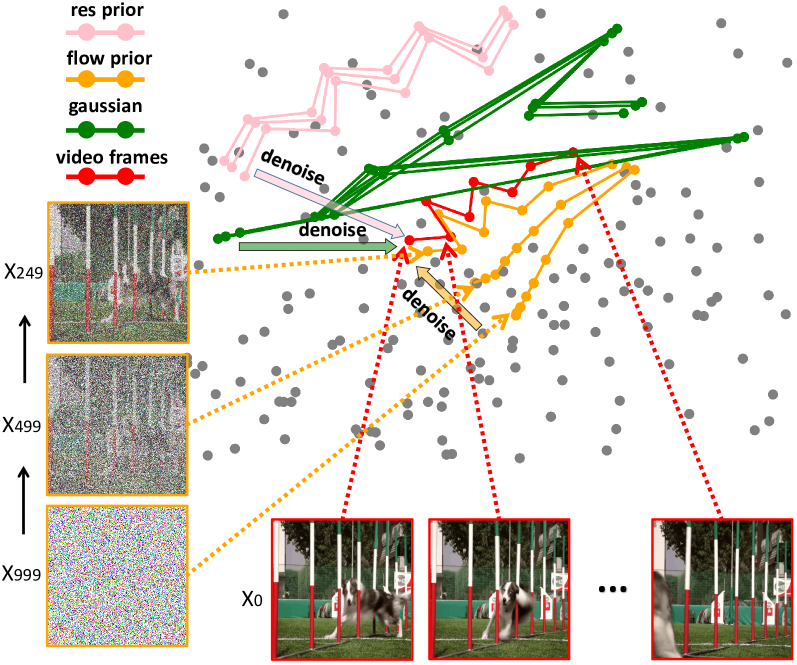
- Pure noise initialization in video diffusion leads to disjointed frames because standard Gaussian noise destroys the correlation between consecutive frame latents
- Standard denoising training does not directly optimize for aesthetic quality or temporal smoothness, leading to artifacts like blur and flickering
Concrete Example:
When generating a video from a prompt, standard methods might produce frames where the background shifts randomly or the subject's appearance changes (flickering). In contrast, Control-A-Video uses edge maps and optical flow priors to ensure the subject moves smoothly and stays consistent across frames.
Key Novelty
Spatio-Temporal Reward Feedback Learning (ST-ReFL) & Motion-Adaptive Noise Priors
- Initializes video noise using motion priors (optical flow or pixel residuals) from a reference video rather than independent Gaussian noise, preserving latent correlation between frames
- Optimizes the video diffusion model using a feedback loop (ST-ReFL) where multiple reward models score generated clips for aesthetic quality and motion smoothness, updating the model to maximize these scores
- Uses the first frame as a content prior during training, allowing the model to focus on learning motion dynamics rather than memorizing static content
Architecture
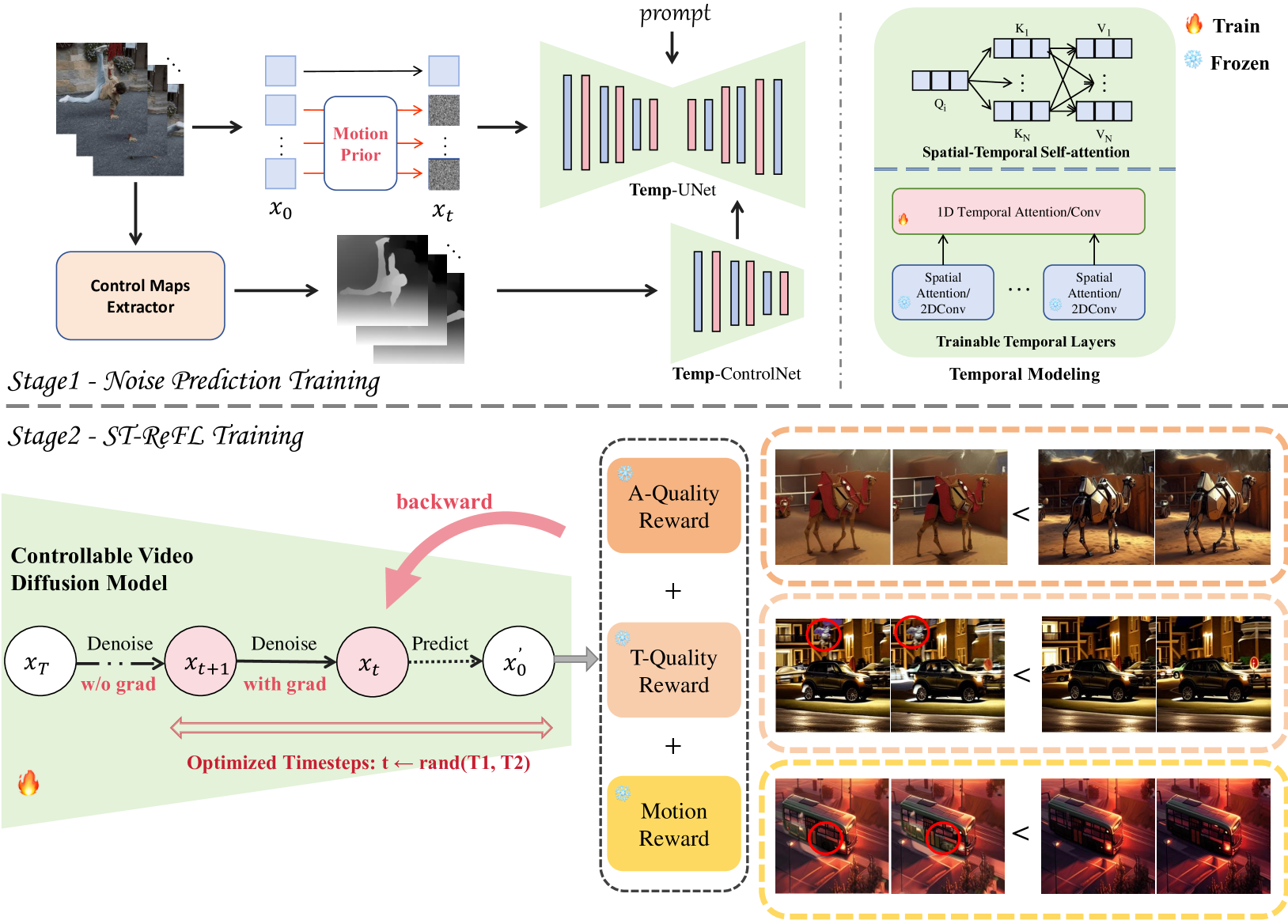
The overall framework of Control-A-Video, including the network architecture with temporal layers, the noise initialization strategy, and the ST-ReFL training loop.
Evaluation Highlights
- Achieves state-of-the-art results in controllable text-to-video generation compared to baselines like Tune-A-Video and ControlNet-Video
- Experiments demonstrate noticeable reduction in flickering artifacts and improved aesthetic appeal through ST-ReFL optimization
- Successfully disentangles content and temporal modeling by conditioning generation on the first frame, enabling auto-regressive generation of longer videos
Breakthrough Assessment
7/10
Significant for introducing reward feedback learning (RL-like optimization) to the video diffusion domain and proposing effective noise initialization strategies for temporal consistency. However, relies heavily on existing T2I backbones.