📝 Paper Summary
Reward Redistribution
Causal Reinforcement Learning
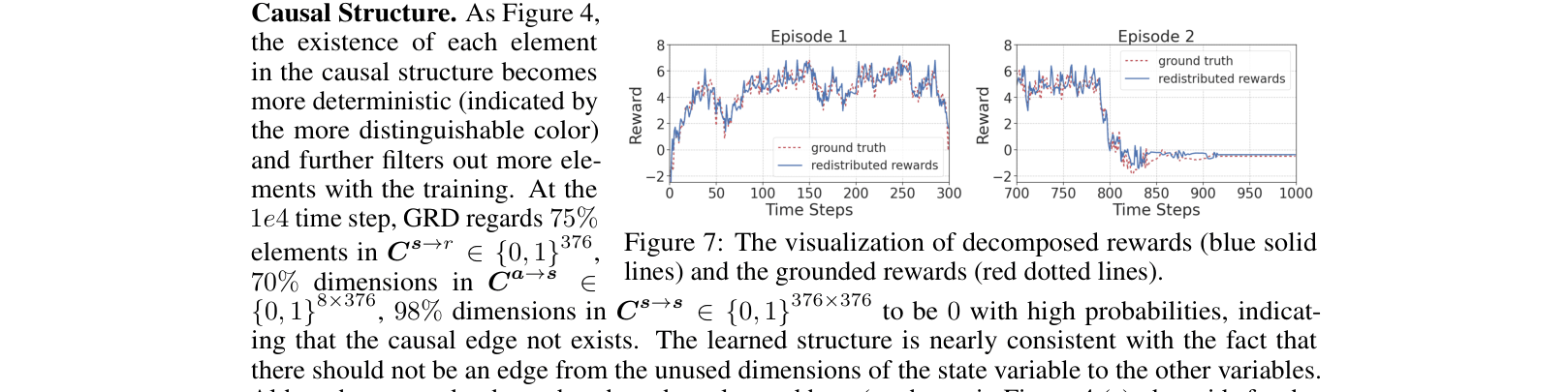
Return Decomposition
Generative Return Decomposition (GRD) recovers the underlying causal structure of Markovian rewards to decompose delayed returns into interpretable proxy rewards and identify a minimal state representation for efficient policy learning.
Core Problem
In reinforcement learning with delayed or episodic rewards, it is difficult to determine which specific state-action pairs contributed to the final outcome, leading to inefficient policy optimization.
Why it matters:
- Standard RL struggles with sparse/delayed feedback because the credit assignment problem is ambiguous without immediate rewards
- Existing return decomposition methods use uninterpretable models (like LSTMs) or hand-designed rules, failing to explain *why* a state-action pair is valuable
- Including irrelevant state dimensions in the policy input adds noise and complexity, slowing down convergence in high-dimensional environments
Concrete Example:
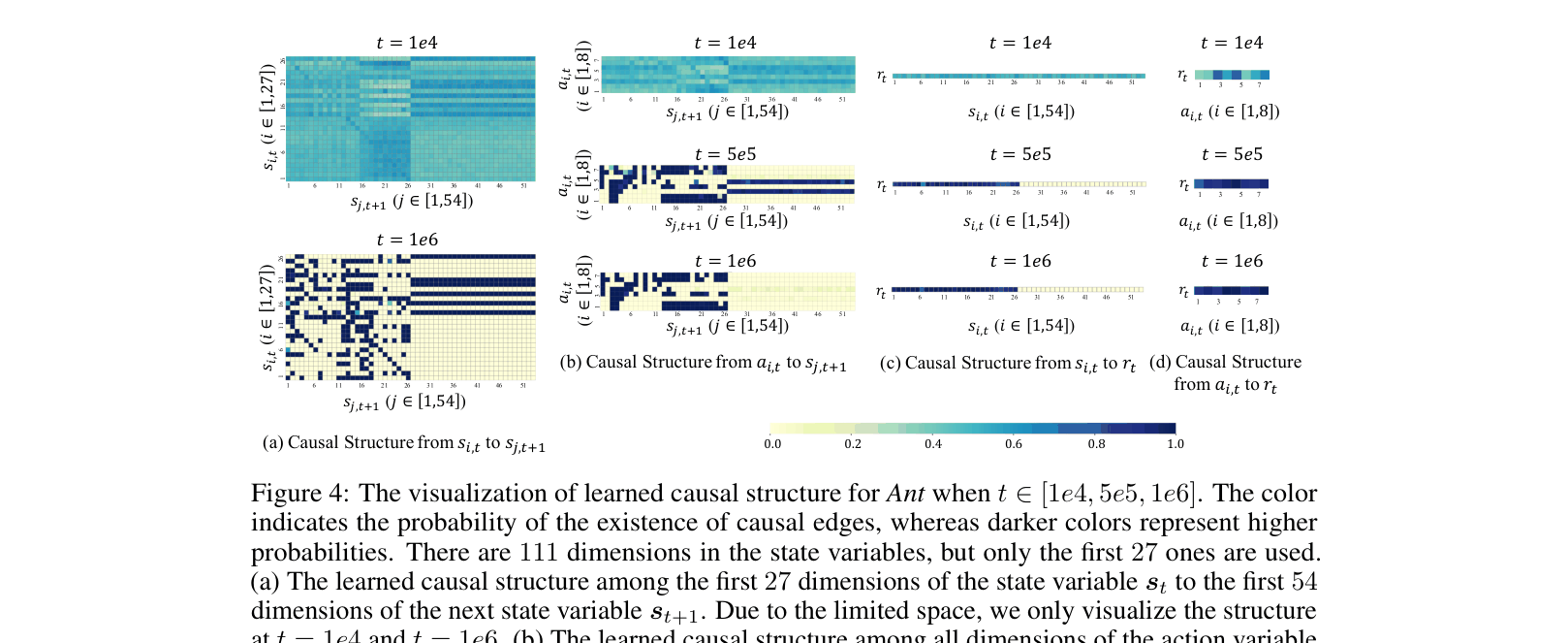
In the 'Ant' robot task, the robot has 111 state dimensions, but 84 are unused noise. A standard RL agent might struggle to learn which dimensions matter for the delayed episode reward, whereas GRD identifies that only specific dimensions causally affect the reward.
Key Novelty
Generative Return Decomposition (GRD)
- Models the long-term return as the causal effect of a sequence of unobserved Markovian rewards within a generative process
- Uses a Dynamic Bayesian Network (DBN) to explicitly learn binary masks representing causal edges between states, actions, and rewards
- Derives a 'compact representation' (minimal sufficient state set) containing only state dimensions that causally influence the reward, filtering out noise for the policy
Architecture
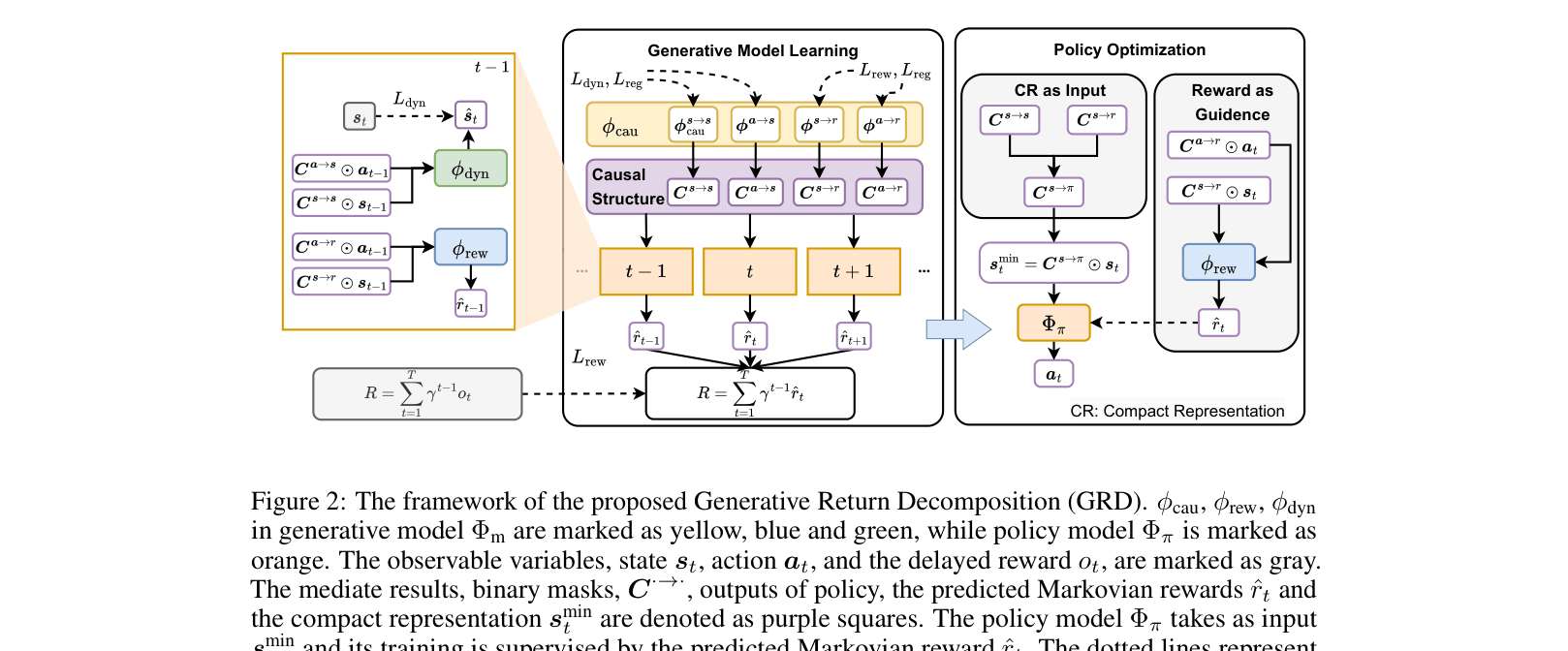
The framework of GRD showing the interplay between the Generative Model (causal discovery) and the Policy Model.
Evaluation Highlights
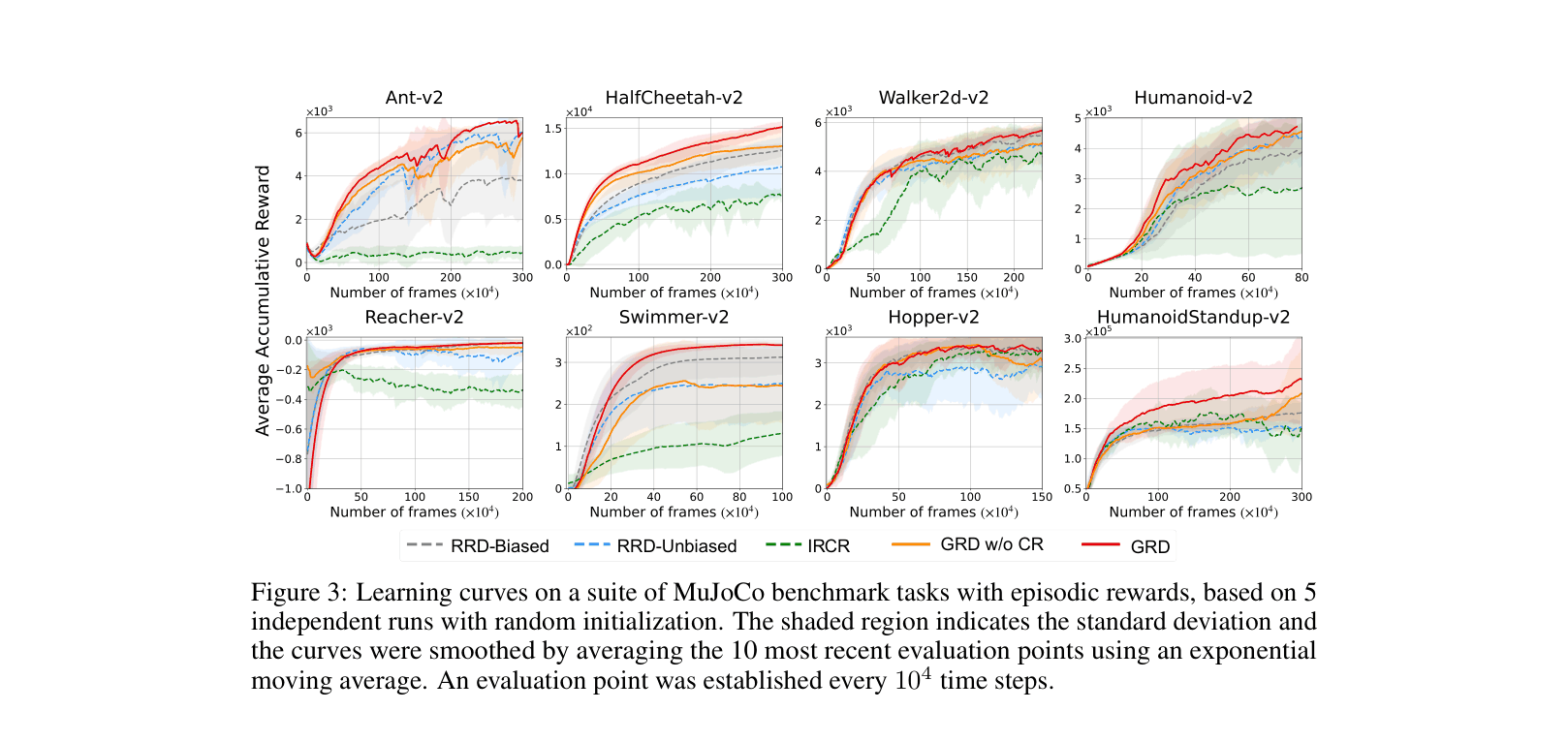
- Outperforms state-of-the-art RRD and IRCR on 8 MuJoCo tasks with episodic rewards, achieving ~1.5x higher return on HalfCheetah
- Achieves superior sample efficiency in high-dimensional state spaces (e.g., HumanoidStandup with 376 dims) by filtering irrelevant features
- Demonstrates robustness to Gaussian noise added to irrelevant state dimensions, maintaining performance while baselines degrade
Breakthrough Assessment
8/10
Strong theoretical grounding in causal identifiability combined with practical state-of-the-art performance on standard benchmarks. The ability to interpret *why* rewards are assigned via causal graphs is a significant advance over black-box return decomposition.