📝 Paper Summary
Preference-based reward learning
Reinforcement Learning from Human Feedback (RLHF)
Reward functions learned from preferences often fail to train new agents from scratch despite working for the original agent, a failure mode exacerbated by high-performing data collectors.
Core Problem
Learned reward functions frequently overfit to the specific trajectory distribution of the agent used to collect data, making them fragile when used to train new agents (relearning).
Why it matters:
- Practitioners assume a learned reward captures the task intent and can be reused to train better policies or transfer to new architectures
- Evaluating only the 'sampler' agent (trained alongside the reward) masks severe robustness issues, creating a false sense of security in RLHF systems
Concrete Example:
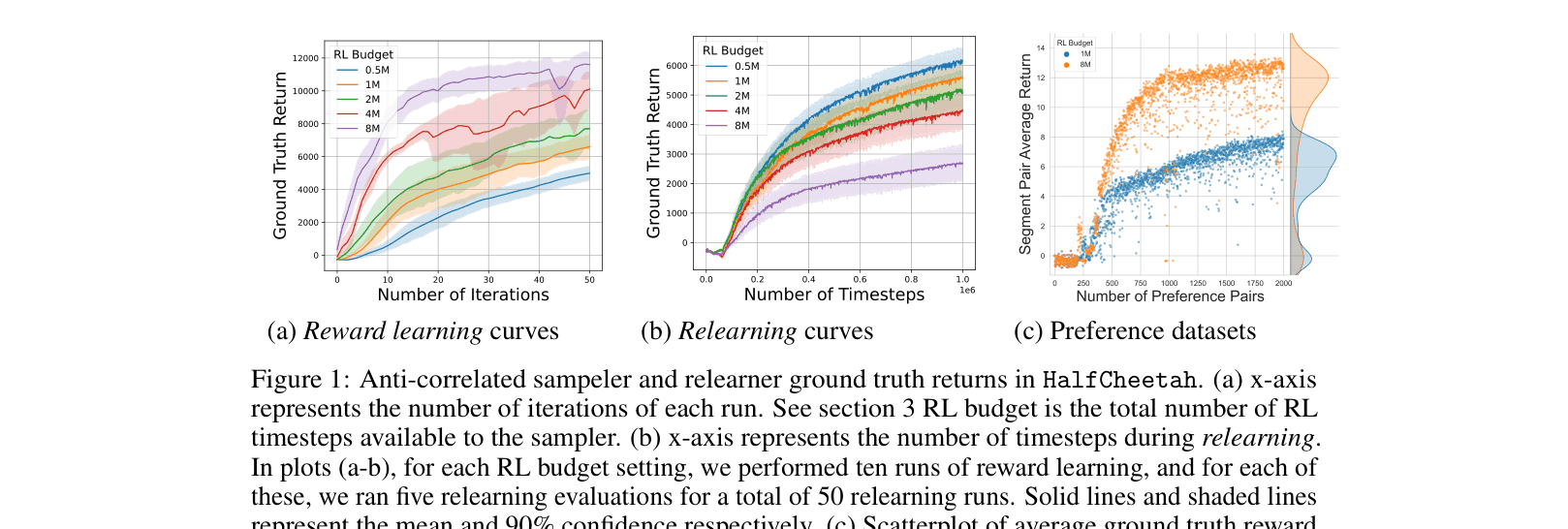
In HalfCheetah, a reward model trained with 8 million steps of interaction produces a high-performing 'sampler' agent but fails catastrophically when used to train a fresh 'relearner' agent, yielding near-zero returns because the reward model overfits to the sampler's narrow, high-reward distribution.
Key Novelty
Systematic Evaluation of Relearning Failures
- Formalize 'relearning evaluation' as a stress test: freezing a learned reward and training a randomly initialized agent from scratch to detect overfitting
- Identify an 'anti-correlation' phenomenon where training the data-collecting agent *longer* (better performance) actually degrades the learned reward's ability to train new agents
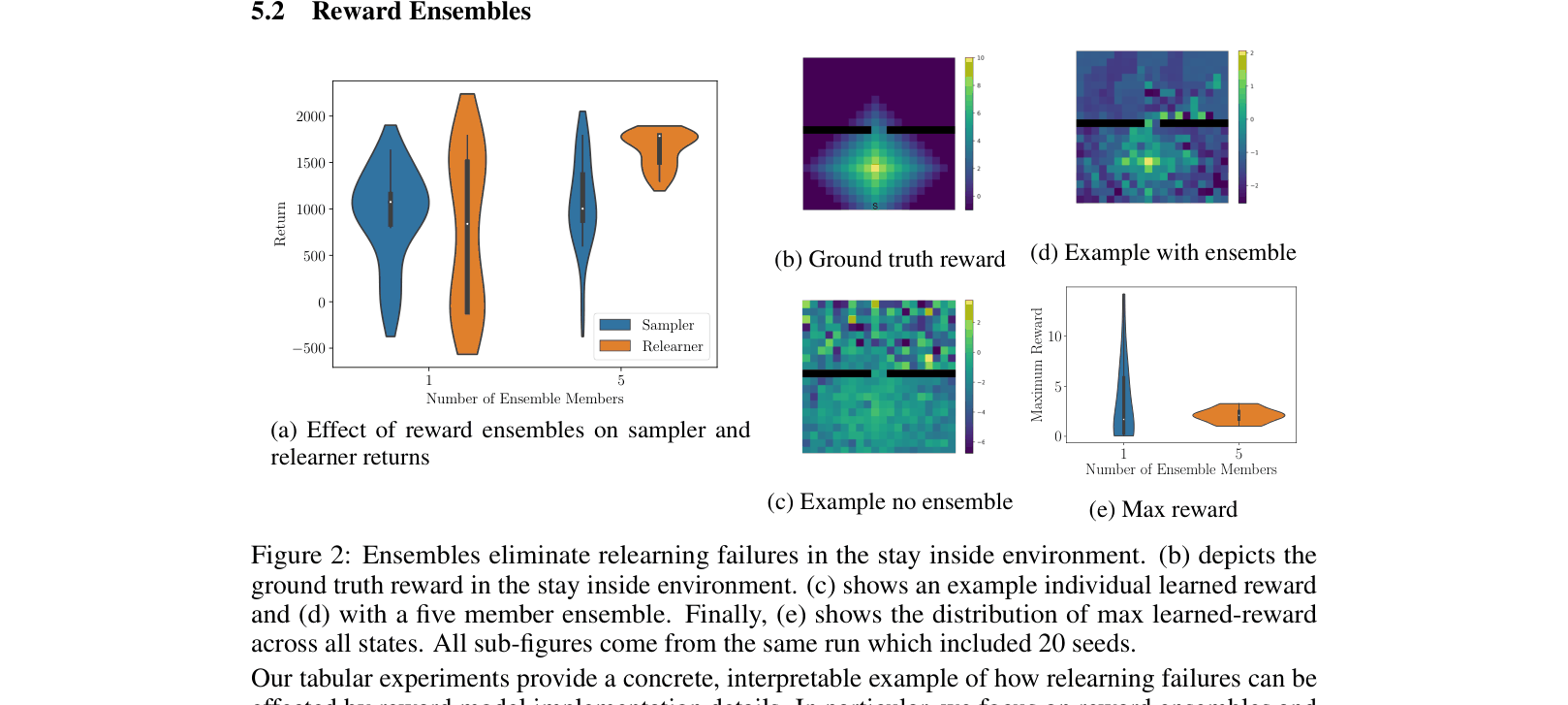
- Demonstrate that reward ensembles can mitigate these failures in tabular settings by smoothing out 'reward delusions' (spurious high rewards) in off-distribution regions
Architecture
Implicit workflow: Sampler generates data -> Reward Model trains -> Sampler updates. Then, separate Relearner trains on frozen Reward.
Evaluation Highlights
- In HalfCheetah, increasing the data collector's training budget from 1M to 8M steps causes relearner performance to drop from ~4000 to <0 return
- In the 'Stay Inside' tabular task, using a 5-member reward ensemble ensures 100% of relearners match sampler performance, whereas single rewards yield high failure rates
Breakthrough Assessment
7/10
Important empirical study revealing a critical flaw in standard RLHF evaluation protocols. While it suggests ensembles as a fix, the primary contribution is diagnosing the 'fragility' phenomenon.