📝 Paper Summary
LLM Alignment
Reinforcement Learning from AI Feedback (RLAIF)
Direct Alignment from Preferences (DAP)
OAIF aligns language models by sampling two responses from the current policy during training, obtaining real-time preferences from an LLM annotator, and updating via standard DAP losses.
Core Problem
Standard DAP methods (like DPO) rely on fixed offline datasets, leading to distribution shifts between the training data and the model's current policy (off-policy learning).
Why it matters:
- Offline datasets prevent the model from getting feedback on its own evolving generations, limiting performance compared to online RL methods.
- RLHF addresses this but requires complex setups with separate reward models and value functions, which are computationally expensive and unstable.
- Existing online methods often still rely on reward models trained on offline data, which doesn't fully solve the distribution shift issue.
Concrete Example:
A model trained on a fixed dataset of high-quality summaries might eventually generate summaries better than the dataset average. If it never gets feedback on these new, better outputs, it stops improving. OAIF continually rates the model's *current* best outputs against each other.
Key Novelty
Online AI Feedback (OAIF)
- Replaces the fixed preference dataset with a dynamic process: sample pairs from the *current* model, then ask an external LLM to rank them immediately.
- Converts offline DAP algorithms (DPO, IPO, SLiC) into online, on-policy algorithms without needing a separate reward model or PPO.
- Provides a lightweight way to control model behavior (e.g., length) just by changing the prompt given to the annotator LLM.
Architecture
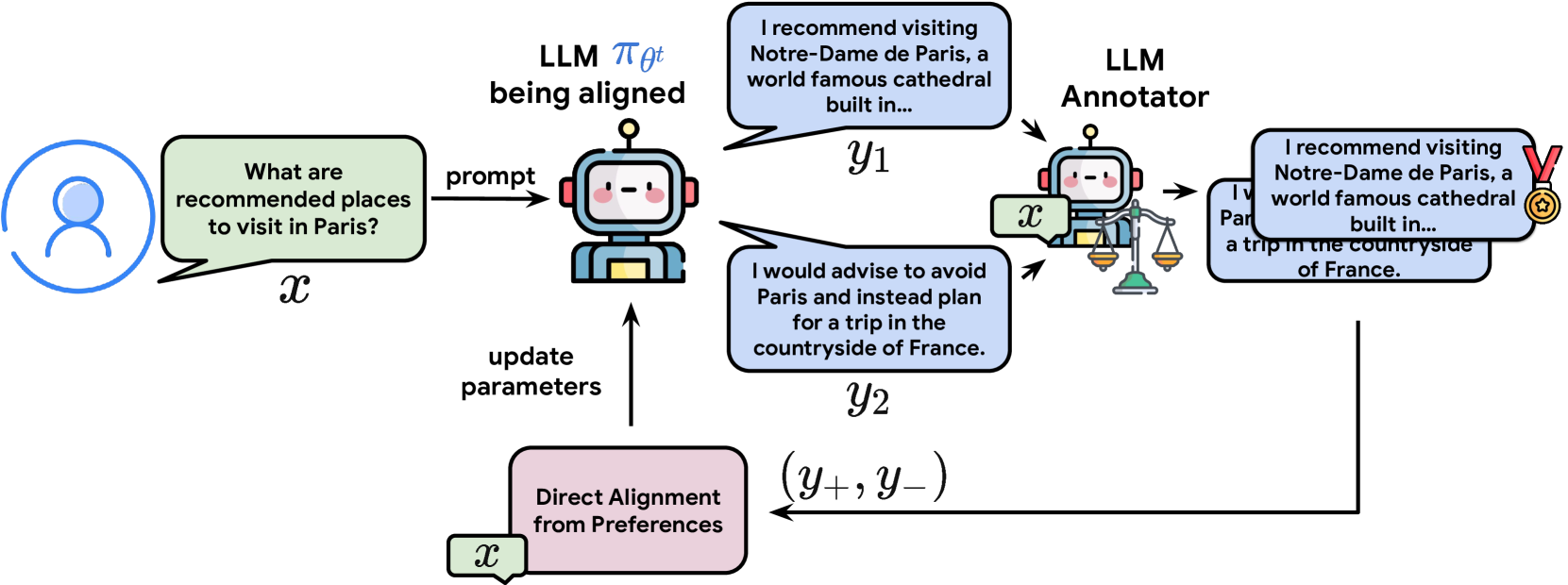
The OAIF training loop compared to offline DAP.
Evaluation Highlights
- Human raters prefer OAIF-DPO over standard RLHF and RLAIF 58.00% of the time on the TL;DR summarization task.
- Online versions of DAP methods (DPO, IPO, SLiC) achieve a ~66% average win rate over their offline counterparts in human evaluation.
- Successfully controls response length: prompting the annotator to prefer shorter summaries reduced length from ~120 to ~40 tokens while maintaining quality.
Breakthrough Assessment
8/10
Elegantly bridges the gap between simple offline methods (DPO) and powerful online methods (RLHF) without the complexity of PPO or reward model training. Strong empirical results confirm the value of on-policy feedback.