📝 Paper Summary
Conditional Diffusion Models
Generative AI Control
Theoretical Deep Learning
RCGDM leverages pseudo-labeled conditional diffusion to generate high-reward samples, theoretically proving this process recovers data subspaces and acts like off-policy bandit learning to balance reward maximization against distribution shift.
Core Problem
Directing generative models to maximize rewards (e.g., safety, aesthetic scores) often forces them off the data manifold, creating a conflict between sample fidelity and reward optimization.
Why it matters:
- Blindly maximizing rewards in applications like protein design or safe RL can produce invalid or dangerous samples that fail to respect physical or logical constraints
- Existing heuristic guidance methods lack statistical guarantees regarding how well they approximate the target distribution or how much the reward actually improves
- Balancing exploration (finding high rewards) and exploitation (staying near data) is theoretically opaque in diffusion models
Concrete Example:
In text-to-image generation, increasing the guidance for a 'colorful' image too much (high target reward) might destroy the image structure, resulting in a chaotic, oversaturated blob rather than a high-quality colorful photo.
Key Novelty
Reward-Directed Conditional Diffusion (RCGDM) with Subspace Analysis
- Treats reward-directed generation as a semi-supervised problem: learns a reward model on labeled data to pseudo-label massive unlabeled data for conditional training
- Theoretically proves that the conditional score network implicitly learns the low-dimensional latent subspace of the data, enabling high-fidelity generation
- Establishes a formal connection between generative diffusion and off-policy bandit learning, bounding the reward gap using bandit regret terms
Architecture
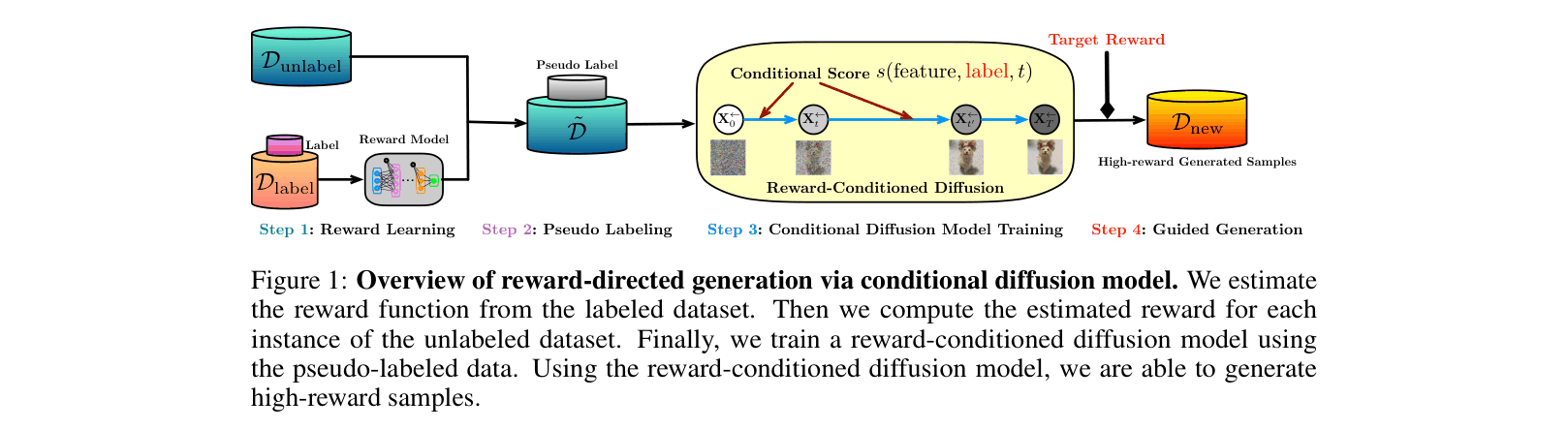
Overview of the RCGDM pipeline: Reward Learning -> Pseudo Labeling -> Conditional Diffusion Training -> Guided Generation.
Evaluation Highlights
- Proves subspace recovery error scales with $\tilde{O}(1/\sqrt{n_1})$, meaning the model effectively identifies the latent data manifold from unlabeled data
- Demonstrates in text-to-image generation that increasing reward targets improves predicted rewards by ~6x (target 16 vs 1) but increases distribution shift error, validating the theoretical trade-off
- Shows in simulation that on-support diffusion error remains linear for small reward shifts but becomes quadratic when the target reward exceeds the latent dimension ($a > d$)
Breakthrough Assessment
8/10
Significant theoretical contribution connecting diffusion models to bandit theory and subspace learning. Provides the first statistical guarantees for reward improvement in conditional diffusion, though empirical SOTA comparisons are secondary to the analysis.
