📊 Experiments & Results
Evaluation Setup
Zero-shot evaluation on Out-Of-Distribution (OOD) datasets and cross-domain tasks.
Benchmarks:
- ImageNet-A (Image Classification (OOD))
- ImageNet-V2 (Image Classification (OOD))
- ImageNet-R (Image Classification (OOD))
- MSCOCO (Text-Image Retrieval / Image Captioning)
- Flickr30k (Text-Image Retrieval / Image Captioning)
Metrics:
- Top-1 Accuracy
- Recall@K (R@1, R@5, R@10)
- CIDEr
- SPICE
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Classification results on ImageNet variants show RLCF improving over TPT and standard Zero-Shot CLIP. | ||||
| ImageNet-A | Top-1 Accuracy | 54.8 | 57.1 | +2.3 |
| ImageNet-R | Top-1 Accuracy | 77.0 | 78.2 | +1.2 |
| Retrieval results demonstrate RLCF's ability to adapt text-to-image and image-to-text retrieval in a zero-shot setting. | ||||
| MSCOCO (5k) | Text-to-Image R@1 | 30.4 | 32.6 | +2.2 |
| Flickr30k (1k) | Image-to-Text R@1 | 66.5 | 69.0 | +2.5 |
| Captioning results show improvements in generation quality metrics using CapDec and CLIPCap backbones. | ||||
| Flickr30k | CIDEr | 12.7 | 14.9 | +2.2 |
Experiment Figures
Bar chart comparing average Top-1 accuracy improvements of RLCF against Zero-Shot CLIP and TPT across 15 datasets.
Main Takeaways
- RLCF consistently improves zero-shot performance across three distinct tasks: classification, retrieval, and captioning.
- The method works effectively with different backbones (ResNet, ViT) and adaptation strategies (prompt tuning, weight tuning).
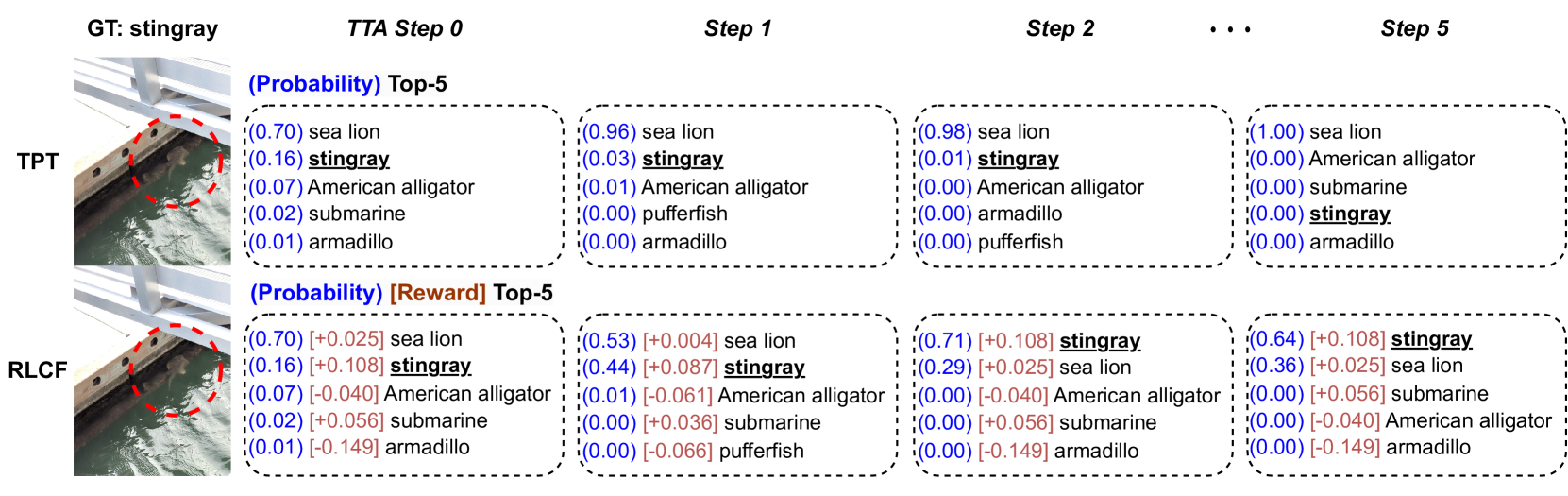
- Using CLIP as a reward signal provides a reliable proxy for ground truth in unsupervised test-time settings, preventing the 'blind confidence' issue of entropy minimization.
- The framework allows for task-specific pipelines (e.g., only tuning the query branch in retrieval) while maintaining a unified RL-based optimization core.