📝 Paper Summary
Instruction-based image editing
Reward modeling for diffusion models
Automated data curation
The paper improves image editing models by conditioning them on multi-perspective rewards (instruction following, detail preserving, generation quality) derived from GPT-4o, rather than filtering or refining the noisy training data directly.
Core Problem
Predominant image editing datasets (like InsPix2Pix) are generated by models not designed for editing, leading to noisy triplets with inaccurate instruction following, poor detail preservation, and generation artifacts.
Why it matters:
- Noisy training data limits the performance of state-of-the-art editing models, causing them to hallucinate changes or fail to execute instructions.
- Existing methods that try to filter data or use human feedback (like MagicBrush) are hard to scale or don't cover specific failure modes (following vs. preserving).
- Standard reward mechanisms (like single-score rewards) are insufficient because image quality is multi-dimensional and CLIP encoders are insensitive to scalar reward values.
Concrete Example:
In the InsPix2Pix dataset, an instruction 'make the glasses green' might result in a ground-truth image where the glasses remain unchanged but the background color shifts. Training on this teaches the model to ignore instructions and hallucinate background edits.
Key Novelty
Multi-Reward Condition (MRC) Framework
- Instead of discarding noisy data, the model is trained with explicit 'quality labels' (rewards) as auxiliary inputs, teaching it to distinguish between good and bad editing behaviors.
- Rewards are decomposed into three distinct perspectives: instruction following, detail preserving, and generation quality, each with a scalar score and text feedback.
- At inference time, the model is guided to generate high-quality edits by manually setting these reward condition inputs to their maximum possible values (scores of 5).
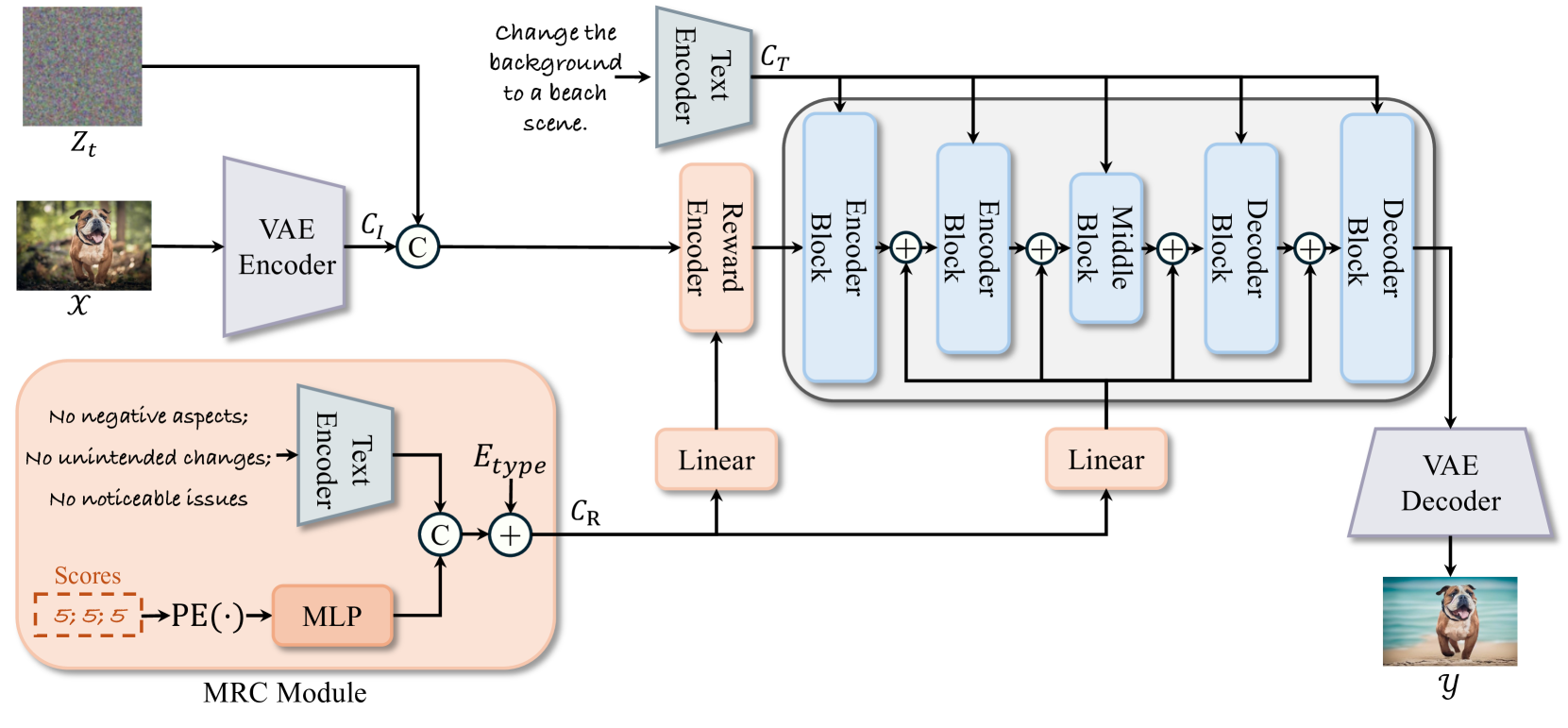
Architecture

The Multi-Reward Condition (MRC) framework integrated into a Stable Diffusion editing pipeline.
Evaluation Highlights
- +9.4% improvement in Instruction Following accuracy on the Real-Edit benchmark when adding Multi-Reward to InsPix2Pix (GPT-4o evaluation).
- Outperforms HIVE (a feedback-based baseline) by +6.2% in Instruction Following and +0.33 in Detail Preserving score on Real-Edit.
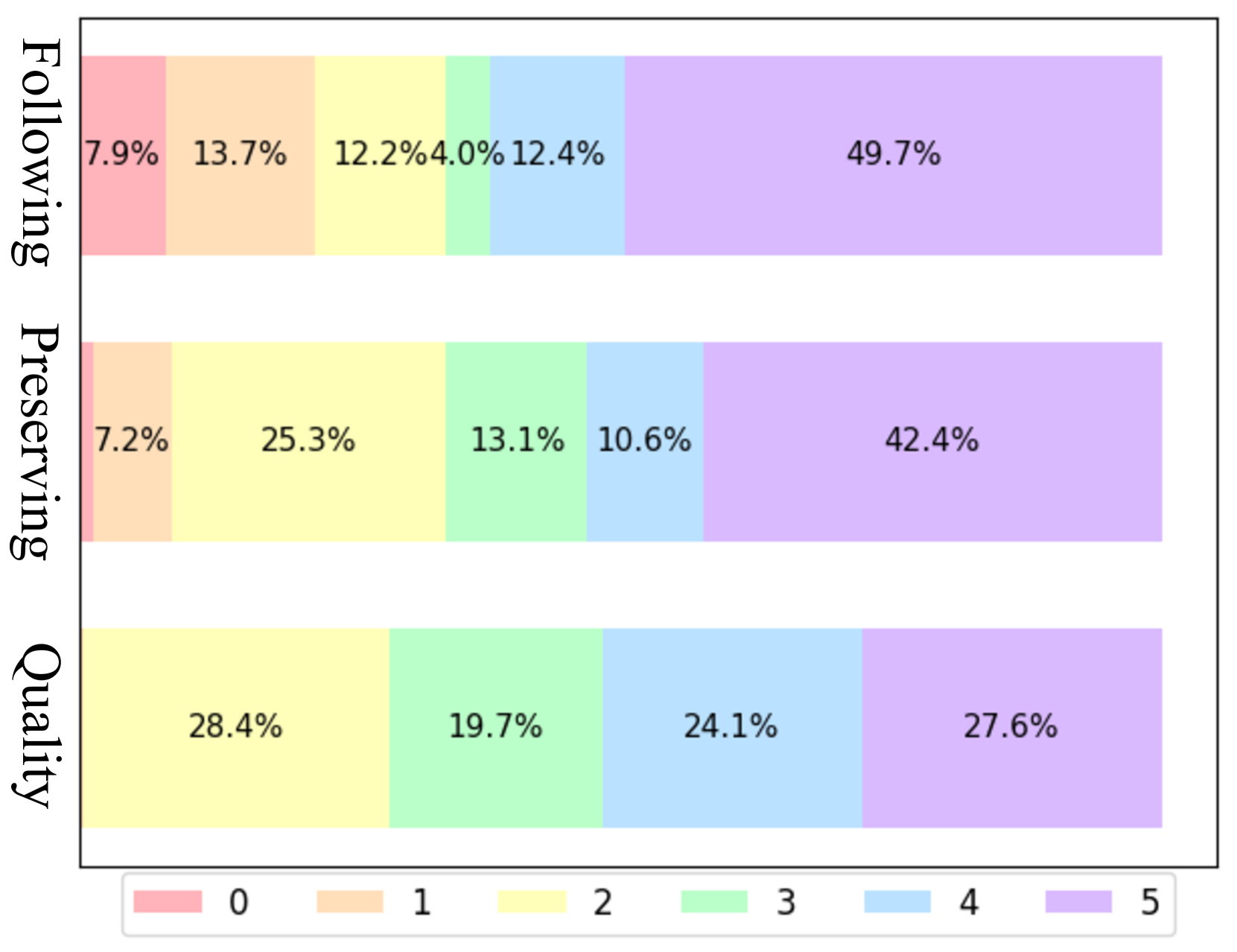
- Achieves state-of-the-art results across all three metrics (Following, Preserving, Quality) in human evaluation, surpassing SmartEdit and HIVE.
Breakthrough Assessment
7/10
A clever, pragmatic solution to the noisy data problem. Instead of expensive cleaning, it effectively 're-labels' noise as low-reward examples. Strong empirical results, though the core architectural change is an auxiliary conditioning branch.