📝 Paper Summary
Video Generation
Model Distillation
Reward Fine-tuning
DOLLAR enables high-quality 4-step video generation by combining variational score and consistency distillation with a memory-efficient latent reward model that bypasses pixel-space decoding.
Core Problem
Diffusion video models require computationally expensive sampling (50+ steps), and existing few-step distillation methods often sacrifice diversity or fail to align with aesthetic rewards due to memory constraints.
Why it matters:
- Standard diffusion sampling is too slow for real-time video applications, often taking minutes per clip
- Current distillation methods like Consistency Distillation (CD) often produce blurry or over-smoothed results in video
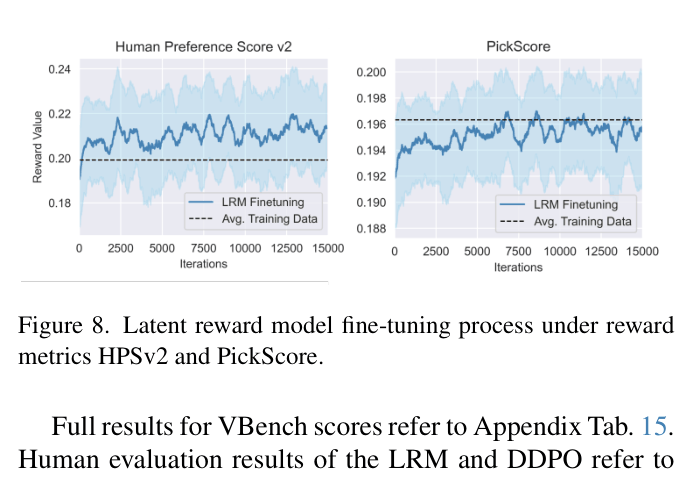
- Fine-tuning with reward models (like HPSv2) is memory-prohibitive for videos because gradients must backpropagate through the decoder and large pixel-space reward networks
Concrete Example:
When distilling a teacher model to 4 steps, standard Variational Score Distillation (VSD) often suffers from mode collapse (low diversity), while Consistency Distillation (CD) lacks fine detail. Furthermore, optimizing for 'aesthetic quality' usually causes Out-Of-Memory (OOM) errors on consumer GPUs because the entire video must be decoded to pixels to calculate the reward.
Key Novelty
DOLLAR (Distillation and Latent Reward Optimization)
- Combines Variational Score Distillation (for quality) and Consistency Distillation (for diversity) to train a few-step student generator
- Learns a lightweight 'Latent Reward Model' (LRM) that approximates complex pixel-space rewards (like aesthetics) directly in the latent space
- Optimizes the diffusion model using gradients from the LRM, avoiding the need to decode videos or backpropagate through massive original reward models
Architecture
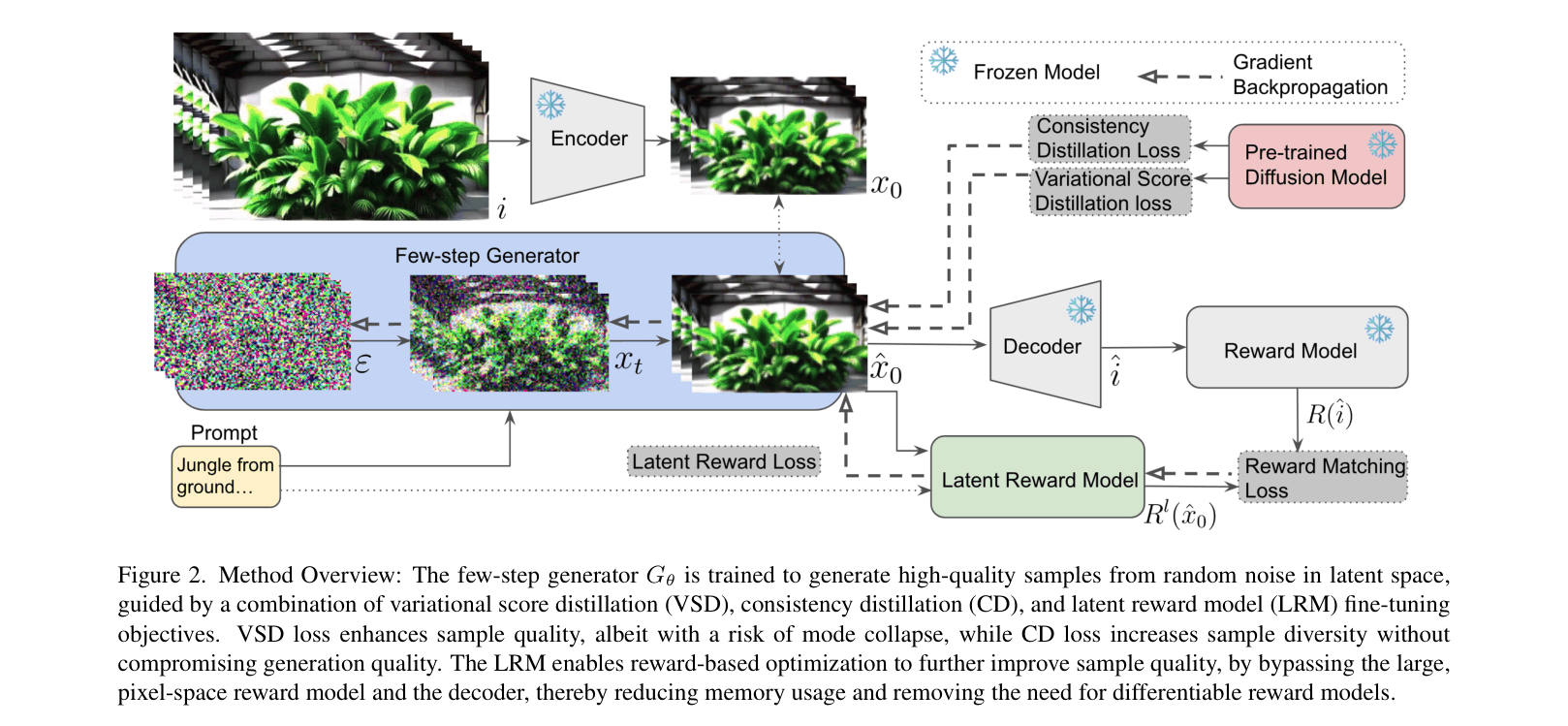
The distillation and fine-tuning framework (training pipeline) showing how VSD, CD, and LRM losses update the student generator.
Evaluation Highlights
- Achieves 82.57 Total VBench Score (using HPSv2 reward), outperforming the 50-step Teacher model (80.25) and baselines like Gen-3 (82.32) and Kling (81.85)
- One-step distillation accelerates diffusion sampling by 278.6x compared to the teacher model, reducing diffusion time to 0.33% of the original
- Student model maintains high generation diversity (Vendi score 1.98) while achieving 4-step inference, surpassing pure VSD (1.91) which suffers from mode collapse
Breakthrough Assessment
8/10
Significantly reduces the computational cost of video generation while improving quality metrics over the teacher. The Latent Reward Model is a clever solution to the memory bottleneck in video RLHF.