📝 Paper Summary
Offline Preference Optimization
Reinforcement Learning from Human Feedback (RLHF)
POWER-DL mitigates reward hacking in offline preference optimization by combining robust reward maximization with dynamic label updates that downweight statistically uncertain preference data.
Core Problem
Offline preference datasets suffer from partial coverage, causing statistical fluctuations where optimization algorithms incorrectly overvalue subpar choices (Type I Reward Hacking) or undervalue decent choices (Type II Reward Hacking).
Why it matters:
- Optimizing imperfect learned rewards often leads to poor performance on true rewards (Goodhart's Law)
- Standard divergence-minimization methods (like DPO) fail to induce sufficient pessimism to prevent the model from overfitting to sparse, unreliable preference data
- Misaligned AI systems may be swayed toward choices that appear favorable only due to noise in the data
Concrete Example:
In a dataset where a high-reward choice 'A' is well-covered but a low-reward choice 'C' is rare, statistical noise might make 'C' appear preferred over 'A'. Standard methods like DPO will aggressively increase the probability of 'C' based on this untrustworthy signal, degrading the model.
Key Novelty
POWER-DL (Preference Optimization via Weighted Entropy Robust Rewards with Dynamic Labels)
- Applies Guiaşu’s weighted entropy to emphasize well-covered, trustworthy data points while ignoring sparse regions where statistical error is high
- Dynamically updates preference labels toward 'stationary labels' during training, which effectively diminishes gradients for samples that contradict the model's evolving understanding (untrustworthy samples)
Architecture
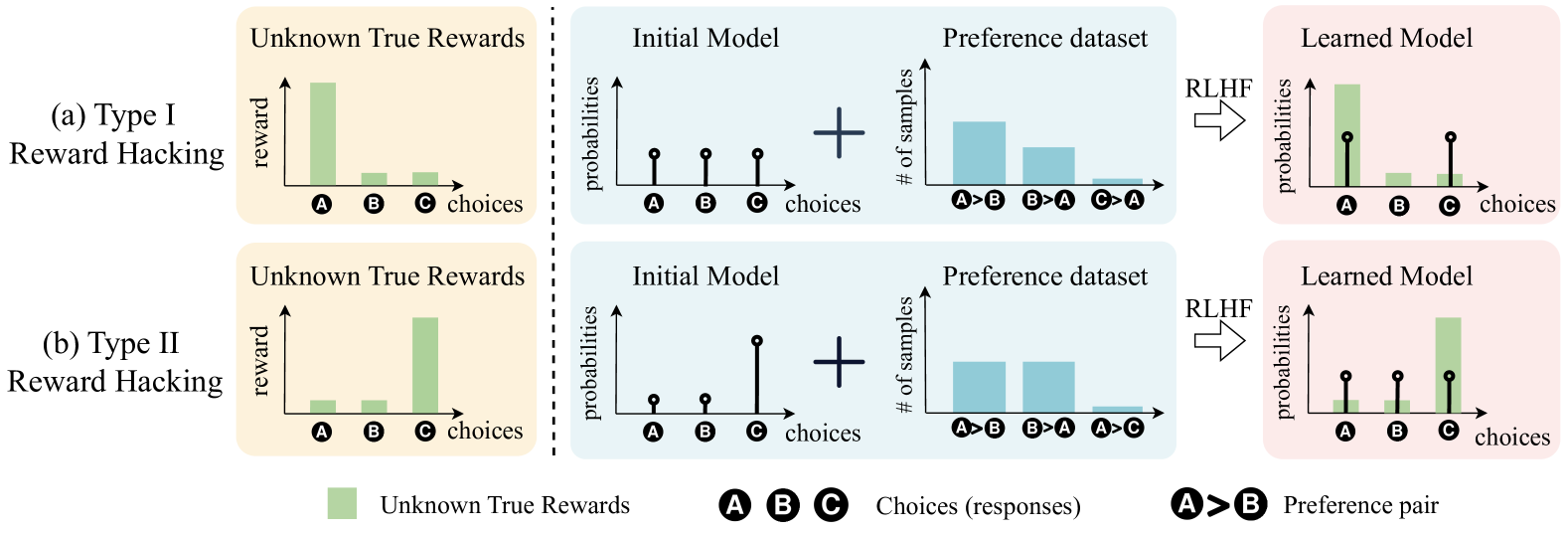
Illustration of Type I and Type II Reward Hacking caused by partial coverage in preference datasets.
Evaluation Highlights
- Achieves up to +13.0 points improvement over DPO on AlpacaEval 2.0 benchmark
- Achieves up to +11.5 points improvement over DPO on Arena-Hard benchmark
- Maintains or improves performance on downstream tasks like mathematical reasoning (GSM8K) while aligning, unlike baselines that often degrade capabilities
Breakthrough Assessment
8/10
Identifies distinct theoretical failure modes of widely used methods (DPO, SimPO) and provides a mathematically grounded solution with significant empirical gains (+13 points).