📝 Paper Summary
Adversarial Imitation Learning
Diffusion Models for RL
DRAIL replaces the standard GAN discriminator in imitation learning with a conditional diffusion model that classifies state-action pairs as expert or agent, providing smoother, more robust rewards for policy training.
Core Problem
Generative Adversarial Imitation Learning (GAIL) training is notoriously brittle and unstable due to the adversarial minimax optimization, often resulting in poor sample efficiency.
Why it matters:
- Imitation learning is crucial when designing reward functions is difficult or unsafe (e.g., robotics), but current adversarial methods are hard to tune.
- Standard GAN discriminators often provide sparse or unstable gradients, making it difficult for the generator (policy) to converge to expert behavior.
- Existing diffusion-based imitation methods (like DiffAIL) use unconditional models that struggle to explicitly distinguish expert vs. agent distributions.
Concrete Example:
In a navigation task, a standard GAIL discriminator might rapidly overfit, giving near-zero rewards for any agent action that slightly deviates from the expert, causing the agent to stop learning. DRAIL's diffusion reward remains informative even for imperfect actions, guiding the agent smoothly toward the expert trajectory.
Key Novelty
Diffusion Discriminative Classifier for Reward Calculation
- Instead of a standard binary classifier, use a conditional diffusion model that learns to denoise a 'real/fake' class label conditioned on the state-action pair.
- Calculate the reward signal based on the diffusion loss (how well the state-action pair fits the expert distribution vs. the agent distribution) using just two reverse diffusion steps.
- Transform the unbounded diffusion loss into a bounded probability [0, 1] using a sigmoid function, creating a stable discriminator for the adversarial learning loop.
Architecture
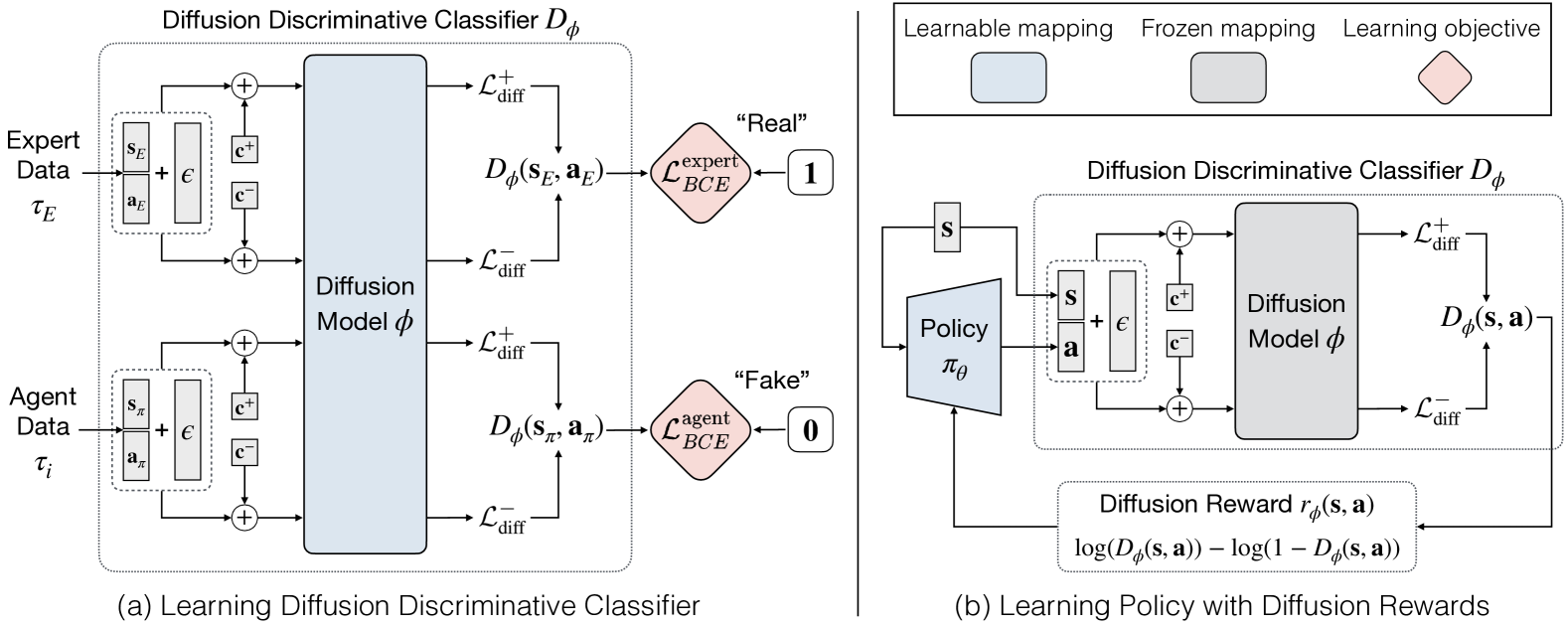
The overall framework of DRAIL. It illustrates the interaction between the Agent (Policy), the Environment, and the Diffusion Discriminative Classifier.
Evaluation Highlights
- Outperforms GAIL and DiffAIL across 8 continuous control tasks (MuJoCo, Meta-World, Adroit), achieving higher average returns.
- Achieves superior sample efficiency, reaching expert-level performance with fewer environment interactions than baselines in tasks like Ant-v2 and Walker2d-v2.
- Demonstrates better generalization to unseen states/goals in navigation tasks compared to Behavioral Cloning and GAIL.
Breakthrough Assessment
7/10
Offers a clever integration of diffusion models into adversarial learning that addresses a known pain point (instability). Results are strong across diverse benchmarks, though the fundamental framework remains adversarial imitation learning.