📝 Paper Summary
Reinforcement Learning from Human Feedback (RLHF)
Reinforcement Learning from AI Feedback (RLAIF)
A self-evolved reward learning framework iteratively refines a reward model using its own high-confidence feedback on unlabeled data, achieving strong performance with minimal human labels.
Core Problem
Training reliable reward models for RLHF typically requires massive amounts of high-quality human preference data, which is expensive, limited, and hard to scale.
Why it matters:
- The scalability of strong LLMs is bottlenecked by the scarcity and cost of human-annotated preference data required for alignment
- Current RLAIF methods often rely on stronger, external LLMs (like GPT-4) for feedback, rather than allowing a model to self-improve efficiently
- Quality of reward models directly dictates the success of reinforcement learning strategies like PPO; poor reward models lead to poor policy optimization
Concrete Example:
In standard RLHF, if a developer only has 10% of the necessary human labels, the resulting reward model will be too noisy to guide PPO effectively, causing the LLM to generate misaligned or low-quality responses.
Key Novelty
Self-Evolved Reward Learning (SER)
- Iterative 'feedback-then-train' loop where the Reward Model (RM) labels its own data and retrains on high-confidence samples
- Curriculum-style learning status detection: The RM first learns to distinguish 'good vs. bad' (Status 1) before progressing to finer-grained comparisons between similar answers (Status 2)
- Adaptive data filtering that selects training samples based on the model's current capability (distinguishing broad quality vs. nuanced differences)
Architecture
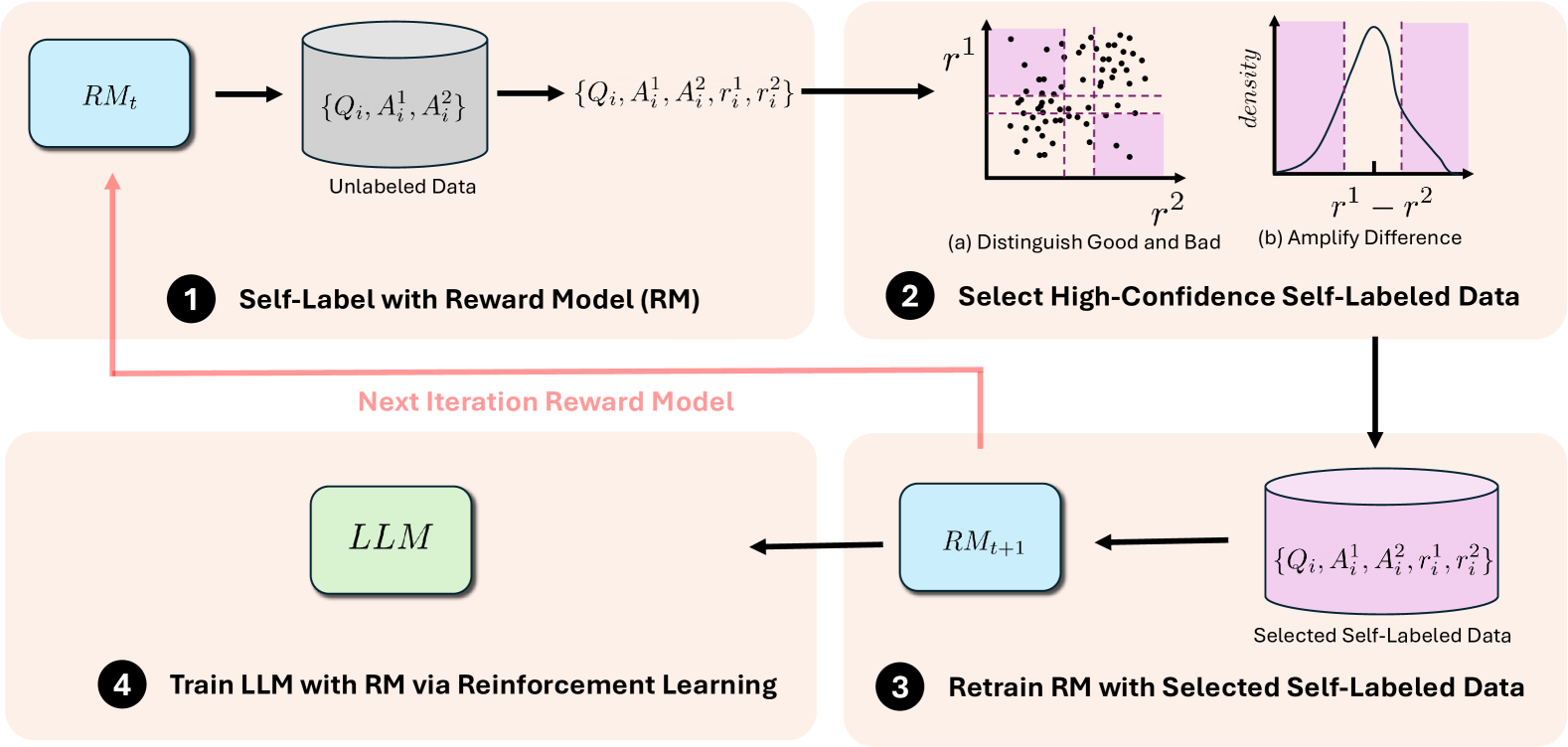
The Self-Evolved Reward Learning (SER) pipeline. It depicts the iterative loop of self-labeling, status identification, data filtering, and retraining.
Evaluation Highlights
- Achieves performance comparable to models trained on full human datasets using only 15% of the annotated seed data
- Improves model performance by an average of 7.88% compared to seed models trained on limited human data
- Convergence analysis shows the method can surpass performance of models trained on the entire human-annotated dataset after multiple iterations
Breakthrough Assessment
8/10
Significantly reduces reliance on human data (using only 15%) while maintaining or exceeding full-data performance. The curriculum-based self-labeling strategy is a robust contribution to data-efficient alignment.