📝 Paper Summary
Reinforcement Learning for Reasoning Models
Reward Model Evaluation
VerifyBench evaluates how well AI models can verify the correctness of reasoning answers against a ground truth reference, revealing significant failures in current models on hard, contentious cases.
Core Problem
Existing reward benchmarks focus on preference ranking (which response is better?) rather than absolute verification correctness (is this response correct given the reference?), failing to capture the needs of reasoning model training.
Why it matters:
- Training advanced reasoning models (like OpenAI o1 or DeepSeek-R1) relies on reference-based rewards to guide complex chains of thought toward correct answers
- Without accurate verification, reinforcement learning (RL) processes may reward incorrect reasoning or hallucinations, degrading model reliability
- Current benchmarks do not assess whether a reward model can reliably distinguish correct from incorrect answers using a reference
Concrete Example:
A reasoning model might produce a mathematically plausible but incorrect derivation. Preference-based benchmarks might rate it highly if it 'looks' better than a messy correct answer. VerifyBench tests if the system can explicitly flag it as 'incorrect' when compared to the ground truth.
Key Novelty
Reference-Based Verification Benchmark (VerifyBench)
- Shifts evaluation from pairwise preference (A vs. B) to absolute correctness verification (Is A correct given Reference G?)
- Constructs a 'Hard' subset based on model disagreement, where top LLMs provide conflicting judgments on the same response, necessitating human ground truth
Architecture
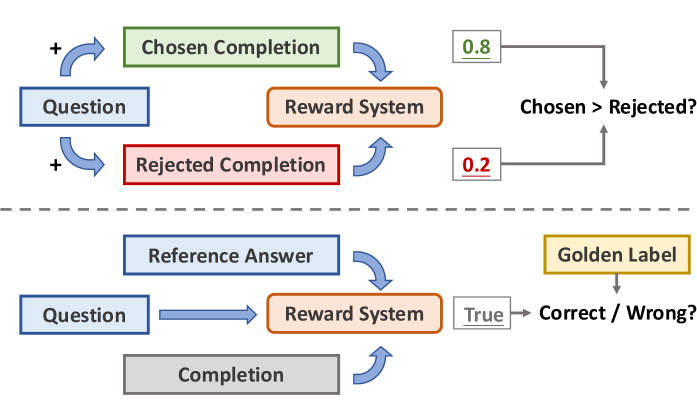
Overview of the VerifyBench construction pipeline
Evaluation Highlights
- On the standard VerifyBench, top models like Qwen3-32B achieve high accuracy (95.8%), showing strong baseline verification capabilities
- On VerifyBench-Hard (contentious cases), performance drops significantly: the best accuracy is only 72.4%, a ~20% decline, indicating struggle with ambiguity
- Small models (<3B parameters) fail at verification: Llama-3.2-3B achieves only ~60.95% accuracy on standard cases, making them unreliable for efficient reward signaling
Breakthrough Assessment
7/10
Important contribution for the specific niche of reasoning model training. Highlights the 'verification gap' in RL pipelines, though the method is primarily dataset construction rather than a new modeling technique.