📝 Paper Summary
Decoding-time alignment
Inference efficiency
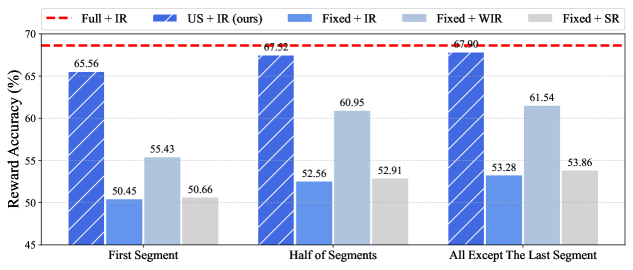
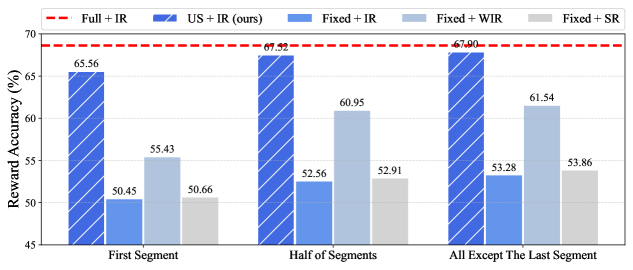
CARDS accelerates alignment by performing rejection sampling on semantically complete segments identified via the LLM's own predictive uncertainty, minimizing redundant generation and reward evaluation.
Core Problem
Decoding-time alignment methods suffer from a trade-off between efficiency and quality: they either evaluate rewards too frequently (per token), causing excessive computation, or generate full sequences before evaluation, wasting compute on rejected outputs.
Why it matters:
- Evaluating reward models at every token (Reward-Guided Search) is computationally prohibitive for real-time applications
- Generating entire responses only to reject them (Best-of-N, Rejection Sampling) results in significant wasted GPU cycles
- Applying traditional reward models to arbitrary incomplete text fragments often yields inaccurate scores, degrading alignment quality
Concrete Example:
In standard Rejection Sampling, an LLM might generate a full paragraph. If the Reward Model rejects it at the end, the entire generation cost is wasted. Conversely, checking the reward after every single word is extremely slow due to frequent RM calls.
Key Novelty
Cascade Reward Sampling (CARDS)
- Performs rejection sampling on small 'semantic segments' rather than individual tokens or full responses, balancing granular control with computational overhead
- Uses 'uncertainty-based segmentation' (tracking next-token entropy) to identify when a semantic unit is complete, ensuring the Reward Model can accurately evaluate the partial text
Architecture
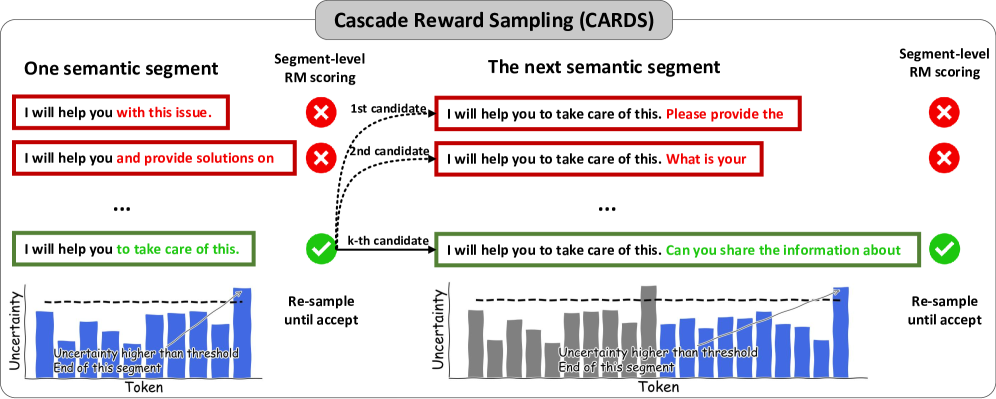
Conceptual illustration of CARDS compared to Best-of-N and Token-level search.
Evaluation Highlights
- Achieves approximately 70% reduction in decoding time compared to existing decoding-time alignment methods
- Secures over 90% win-ties in utility and safety benchmarks evaluated by GPT-4 and Claude-3
Breakthrough Assessment
7/10
Offers a smart, theoretically grounded compromise between token-level and sequence-level search. The use of uncertainty for segmentation to enable accurate partial rewards is a clever insight that addresses a specific limitation of standard RMs.