📝 Paper Summary
Inference-time compute scaling
Reasoning
Allocating test-time compute dynamically based on prompt difficulty (via verifier search or revisions) outperforms static best-of-N baselines and can be more efficient than scaling pre-training parameters.
Core Problem
Current methods for scaling test-time compute (like best-of-N) are applied uniformly regardless of problem difficulty, leading to inefficient compute allocation.
Why it matters:
- Standard scaling laws focus on pre-training, but inference-time compute offers a flexible trade-off that could allow smaller models to outperform larger ones
- Uniform strategies waste compute on easy problems (where simple sampling suffices) and under-allocate on hard problems (which need extensive search)
- Conflicting prior results on the efficacy of self-correction/revision suggest a need for a unified optimal strategy
Concrete Example:
On an 'easy' math problem, a model might get the right answer immediately, making 100 parallel samples wasteful. On a 'hard' problem, 100 parallel samples might all fail because they lack the necessary step-by-step verification or revision depth found in tree search.
Key Novelty
Compute-Optimal Test-Time Scaling Strategy
- Proposes a 'compute-optimal' strategy that dynamically selects the best inference method (e.g., revision vs. parallel sampling vs. search) and hyperparameters based on the prompt's predicted difficulty
- Demonstrates that smaller models with optimal test-time compute can outperform 14x larger pre-trained models on effectively matched FLOPs
- Unifies two mechanisms: modifying the proposal distribution (revisions) and optimizing the verifier (search against PRM)
Architecture
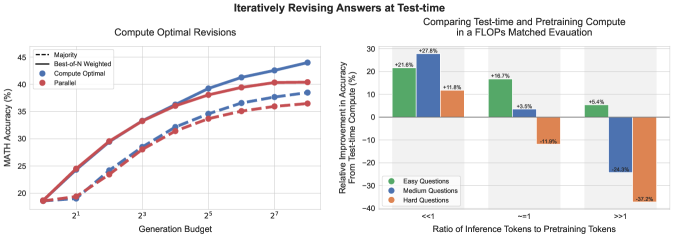
Illustration of three test-time compute mechanisms: (a) Best-of-N (Parallel Sampling), (b) Beam Search (Tree Search with PRM), and (c) Sequential Revisions.
Evaluation Highlights
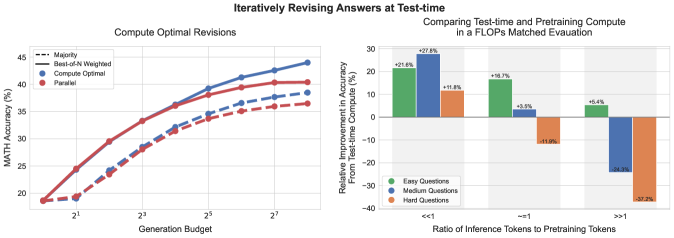
- Compute-optimal strategy improves efficiency by >4x compared to a best-of-N baseline on the MATH benchmark
- In FLOPs-matched evaluation, a smaller base model (PaLM 2-S*) with test-time compute outperforms a 14x larger model on easy/intermediate questions
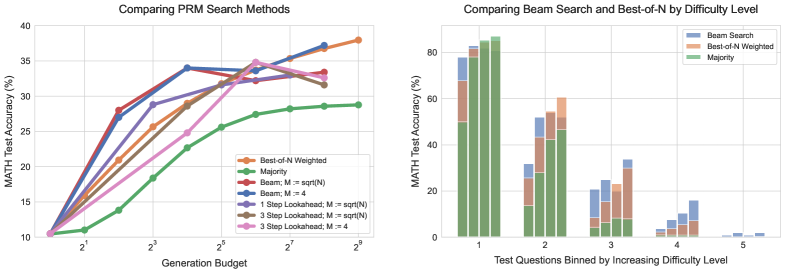
- Beam search outperforms Best-of-N at low budgets but saturates; optimal strategy switches methods adaptively
Breakthrough Assessment
8/10
Provides a rigorous scaling law perspective on inference compute, challenging the dominance of pre-training scaling. The finding that test-time compute can substitute for 14x model scale is significant.